基于大模型的idea提炼:围绕论文和引用提炼idea之ResearchAgent
前言
对本博客比较熟悉的朋友知道,我司论文项目组正在基于大模型做论文的审稿(含CS英文论文审稿、和金融中文论文审稿)、翻译,且除了审稿翻译之外,我们还将继续做润色/修订、idea提炼(包含论文检索),是一个大的系统,包含完整的链路
由于论文项目组已壮大到18人,故目前在并行多个事,且我也针对idea提炼做一下技术探索,本文解析关于idea提炼的两篇论文
- 我司论文项目组三太子在内部18人大群里4.14发的这篇:ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Mode
- // 待定
第一部分 ResearchAgent: 围绕论文和引用提炼idea
1.1 从ResearchAgent到ReviewingAgent:idea的生成与其迭代
考虑到LLMs可以处理和分析大量的文献资料,并以超越人类能力的速度和规模处理数据,还可以识别人类研究者可能立即无法察觉的模式、趋势和相关性,从而使LLM能够发现原本未被发现的新的研究机会。 此外,LLM还可以通过进行实验和解释结果来协助实验验证,从而显着加快研究周期
近日,来自韩国的一研究团队便基于LLM做了相关尝试,即研究思路生成,其中包括问题识别、方法开发和实验设计(research idea generation, which involves problem identification, method development, and experiment design)
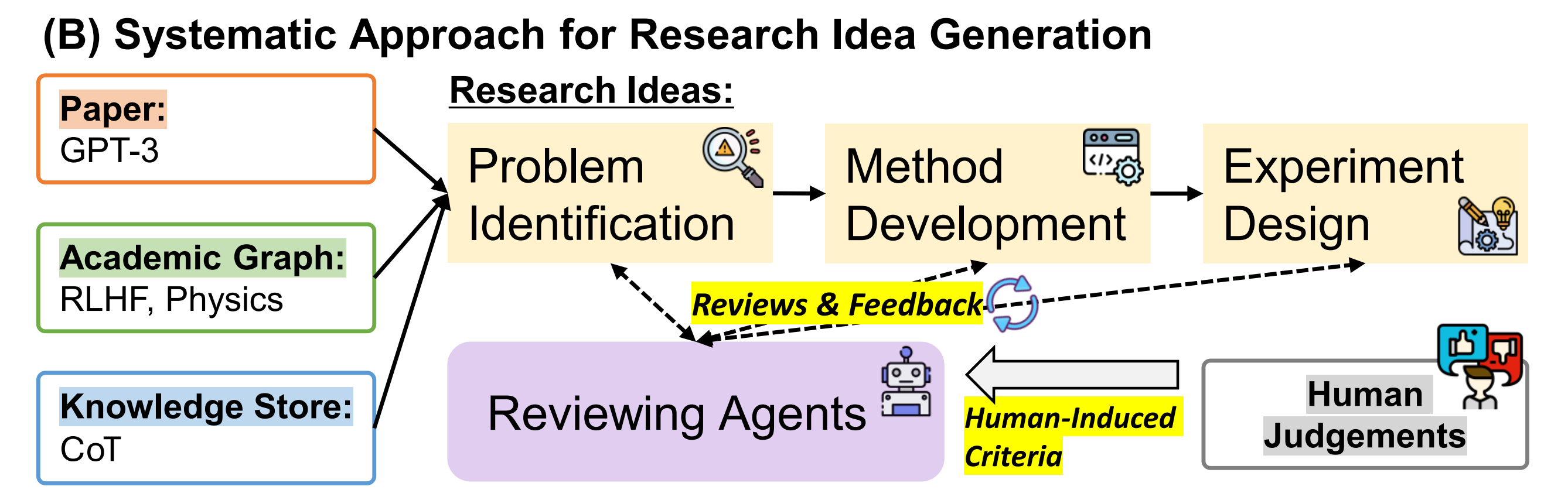
那基于LLM如何提炼idea呢?其实和科研人设计idea的过程差不太多,比如首要的第一步便是阅读大量相关领域的paper,然后提炼出一个逐步的idea,最后针对这个初步的idea反复自我审视及让同行给予反馈、评价,以不断完善该idea
换言之,只阅读某篇论文及其对应的参考文献,从而根据references and citation relationship提炼idea可能不太够
- 首先构建一个知识存储,从科学文章中找到并聚合实体共现。 这个以实体为中心的知识存储捕捉了不同实体之间的相互关联性,并通过潜在的概念和原则为其检索到的知识提供了有价值的见解;我们将展示这些见解对我们的问题非常有价值。
- 此外,为了通过迭代改进增强生成的研究创意,我们设计了多个审查代理,每个代理都对开发的创意生成评论和反馈,具有自己的评估标准
1.1.1 ResearchAgent的流程:基于LLM确定问题、方法、实验
为了完成上述步骤,现有的文献(例如学术出版物)被用作主要来源,提供关于现有知识以及差距和未解答问题的见解
形式上,设为文献,
为由问题
、方法
和实验设计
组成的想法,表示如下:
,其中每个项目由一系列tokens组成,
表示连接操作
然后,idea生成模型 可以表示如下:
,进一步分解为三个子模块步骤:
用于确定问题
用于开发方法
- 以及
用于设计实验
在这项工作中,依赖LLMs来操作 f,利用它们理解和生成学术文本的能力(we operationalize f with LLMs, leveraging their capability to understand and generate academic text),具体而言
LLM接受一个输入token序列 x并生成一个输出token序列 y,表示为:,其中
是模型参数,在训练后固定不变(毕竟进一步微调的成本很高),
是提示模板(prompt template),是一个结构化的格式,概述了上下文(包括任务描述和指示)以指导模型生成所需的输出
从而上述三个子模块便变成了
- 确定问题:
- 确定方法:
- 确定实验:
对于 LLM,我们通过提供一篇核心论文从
开始,然后根据citation graph选择性地纳入后续论文
,这些论文与核心论文直接相关,从而使得用于生成研究想法的 LLM输入更加可管理和连贯「we initiate its literature review process by providing a core paper l0 from L and then selectively incorporating subsequent papers {l1, ..., ln} that are directly related to it based on a citation graph」
对于核心论文及其相关引文(relevant citations)的选择
- 核心论文基于其引用计数进行选择(例如,在3个月内超过100次),通常表示具有高影响力
- 其相关论文(可能非常多)根据其摘要与核心论文的相似性进一步缩小范围,确保得到更加专注和相关的相关paper集合
1.1.2 ResearchAgent的增强:通过实体链接方法提取术语数据库
然后,核心论文及其引用的数量毕竟有限,所能带来的上下文知识范围过于局限,而使得无法提出更好的idea
- 好在我们可以使用现有的现成实体链接方法(实体链接是一个将文本中的不同实体识别并映射到知识库中实体的过程)在任何论文中提取术语数据库(term database),并将这些链接的出现聚合到一个知识库中
we can easily extract the term database whenever it appears in any paper, using existing off-the-shelf entity linking methods and then aggregate these linked occurrences into a knowledge store. - 然后,如果术语数据库在医学科学领域中普遍存在,但在血液学(医学科学的一个子领域)中不太常见,构建的知识库基于除数据库之外的重叠实体捕捉了这两个领域之间的相关性,然后便可在制定有关血液学的想法时提供术语数据库
Then, if the term database is prevalent with in the realm of medical science but less so in hematology (which is a subdomain of medical science), the constructed knowledge store captures the relevance between those two domains based on overlapping entities (other than the database) and then offers the term database when formulating the ideas about hematology.
换句话说,这种方法通过利用各个领域之间的相互关联性,能够提供新颖和跨学科的见解
In other words, this approach enables providing novel and interdisciplinary insights by leveraging the interconnectedness of entities across various field
具体的执行步骤为
- 将知识存储设计为一个二维矩阵
,其中
是已识别的唯一实体的总数,而
以稀疏格式实现
这个知识存储是通过从所有可用的科学文献(由于无法提取所有可用文章中的实体,故这里的目标是针对2023年5月1日之后出现的论文)中提取实体构建的,它不仅计算了个别论文中实体对的共现次数,还量化了每个实体的计数
此外,为了操作化实体提取,我们使用了现有的实体链接器 EL(Scalable zeroshot entity linking with dense entity retrieval),它在特定论文从
,其中
表示出现在
中的实体的多重集(允许重复)
在提取实体后,为了将它们存储到知识存储
中,我们考虑了所有可能的
,其中
,然后将其记录到
- 鉴于这个知识库
使得我们可以通过“知识库 - 形式上,定义从相互连接的论文组中提取的实体如下:
因此,检索前k个相关外部实体的概率形式可以表示如下
其中且
。此外,为了简化起见,通过应用贝叶斯规则并假
设实体是独立的,上面的检索前k个相关外部实体的操作可以近似表示如下:
其中和
可以从二维
- 最终,使用相关实体为中心的知识增强的研究提案生成实例
表示如下:
总之,将这种知识增强的LLM驱动的思路生成方法称为ResearchAgent,下面的三个图中(点击对应图片即可放大查看)



- 左图:通过ResearchAgent提出问题,大意是
我将提供目标论文、相关论文和实体,如下所示:
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
实体:{Entities}
有了提供的目标论文、相关论文和实体,你现在的目标是制定一个研究问题,不仅建立在这些现有研究的基础上,而且要具有原创性、清晰性、可行性、相关性和重要性。 在制定研究问题之前,重新审视目标论文的标题和摘要,确保它仍然是你研究问题识别过程的焦点。
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
然后,在您对上述内容进行审查后,请按照以下格式生成一个带有理论基础的研究问题
研究问题:
理论基础: - 中图,通过ResearchAgent生成方法,大意是
我将提供研究问题、现有研究(目标论文和相关论文)以及实体,如下所示:
研究问题:{researchProblem}
基本原理:{researchProblemRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
实体:{Entities}
根据提供的研究问题、现有研究和实体,你的目标是制定一种方法,不仅利用这些资源,而且力求清晰、创新、严谨、有效和可推广。 在制定方法之前,重新审视研究问题,确保它仍然是你方法开发过程的焦点。
研究问题:{researchProblem}
理论基础:{researchProblemRationale}
然后,在审查上述内容后,请按照以下格式提出你的方法及其理论基础:
方法:
理论基础: - 右图,通过ResearchAgent生成实验设计,大意是
我将提供研究问题、科学方法、现有研究(目标论文和相关论文)和实体,如下所示:
研究问题:{researchProblem}
基本原理:{researchProblemRationale}
科学方法:{scientificMethod}
基本原理:{scientificMethodRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
实体:{Entities}
根据提供的研究问题、科学方法、现有研究和实体,你的目标是设计一个实验,不仅利用这些资源,而且力求清晰、健壮、可重复、有效和可行。 在制定实验设计之前,重新审视研究问题和提出的方法,确保它们仍然是实验设计过程的核心。
研究问题:{researchProblem}
理论基础:{researchProblemRationale}
科学方法:{scientificMethod}
理论基础:{scientificMethodRationale}
然后,在审查上述内容后,请按照实验的格式和理论基础,概述你的实验及其理论基础
实验设计:
理论基础:
1.1.3 ReviewingAgent给反馈:通过与人类偏好对齐的LLM Agents迭代研究思路
当拿到初步的idea之后(包括其对应的问题、方法、实验设计),ReviewingAgents还会根据特定的标准提供review和反馈,以验证生成的研究思路
具体而言,类似于我们使用LLM和模板T实例化ResearchAgent的方法,ReviewingAgents也是类似地实例化,但使用不同的模板,如下面的三个图所示,分别涉及
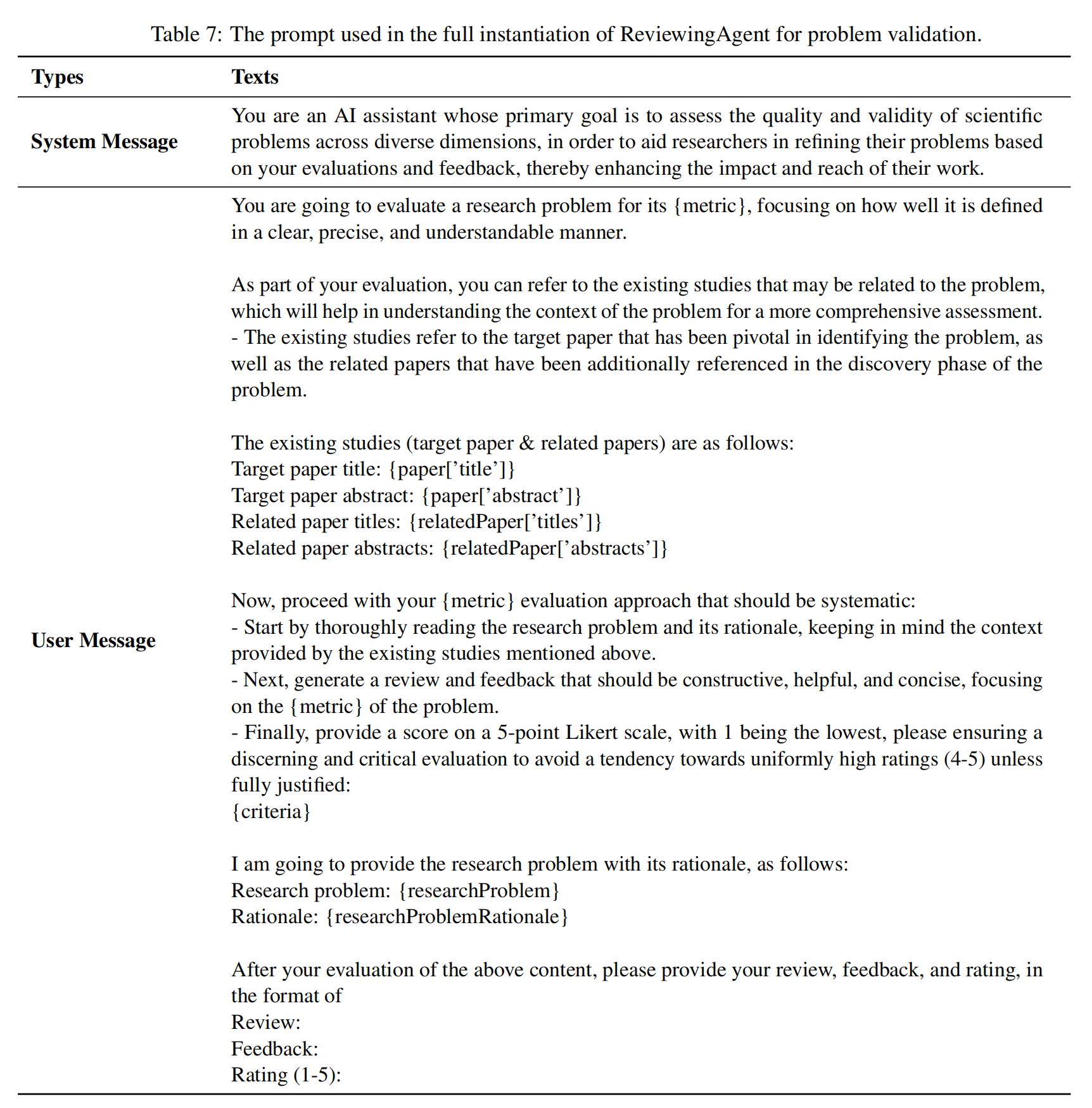


- 对ResearchAgent所提出问题的评价
现有研究(目标论文和相关论文)如下:
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,按照系统的方式进行您的{指标}评估方法:- 首先彻底阅读研究问题及其基本原理,牢记上述现有研究提供的背景信息。
- 接下来,生成一篇评论和反馈,应该是建设性的、有帮助的和简明的,重点关注问题的{指标}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供研究问题及其理论基础,如下所示:
研究问题:{研究问题}
理论基础:{研究问题理论基础}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - ResearchAgent所提出方法的评价
研究问题和现有研究(目标论文和相关论文)如下:
研究问题:{researchProblem}
理由:{researchProblemRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读提出的方法及其基本原理,牢记研究问题所提供的背景和上述现有研究。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简洁的,重点关注方法的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供以下关于提出的方法及其基本原理的信息:
科学方法:{科学方法}
基本原理:{科学方法基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - 所提出的实验设计的评价
研究问题、科学方法和现有研究(目标论文和相关论文)如下所示:
研究问题:{researchProblem}
理由:{researchProblemRationale}
科学方法:{scientificMethod}
理由:{scientificMethodRationale}
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读实验设计及其基本原理,牢记研究问题、科学方法和上述现有研究所提供的背景。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简明扼要的,重点关注
实验的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供设计好的实验及其基本原理,如下所示:
实验设计:{实验设计}
基本原理:{实验设计基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5):
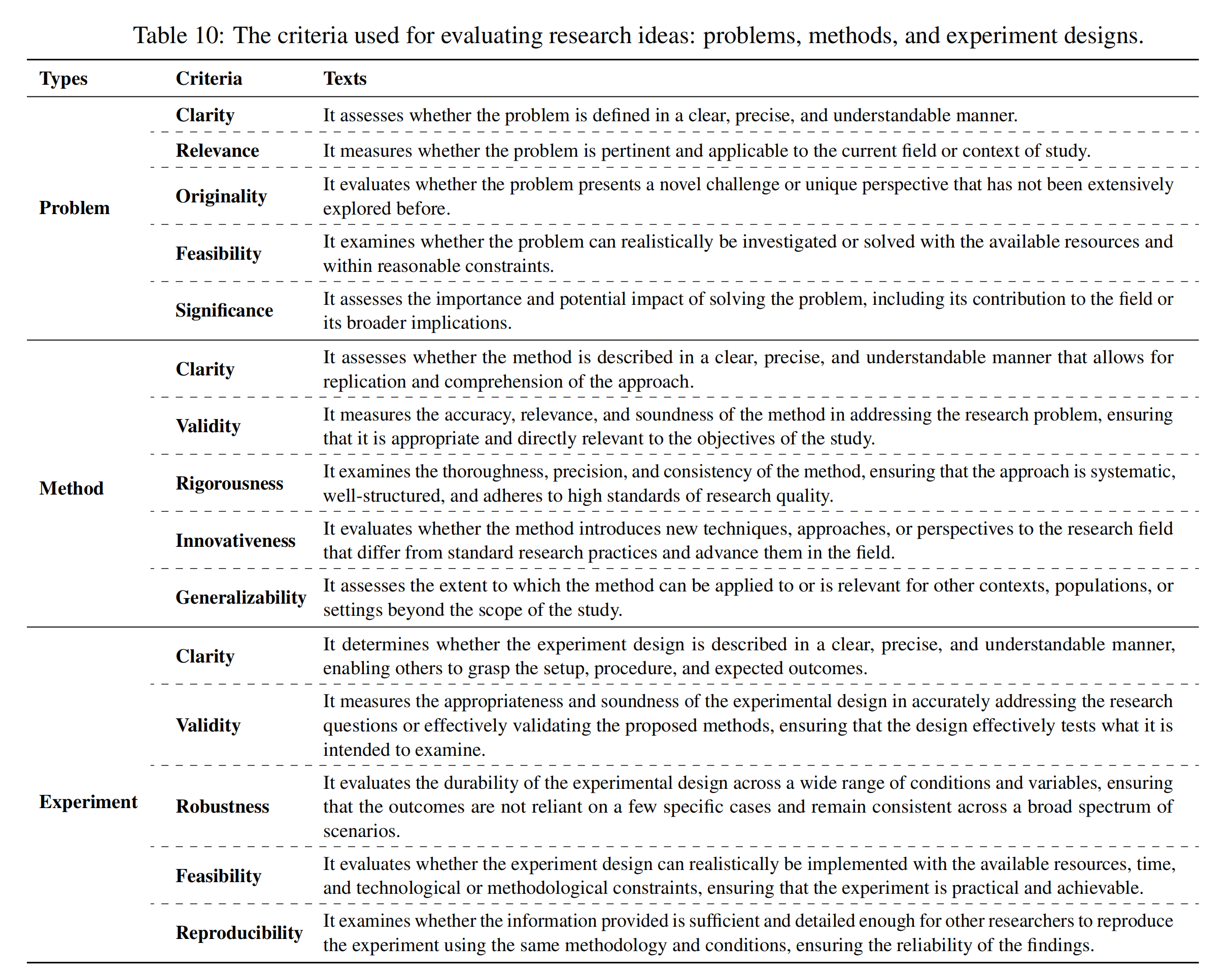
然后,使用ReviewingAgents,根据其各自的五个特定标准对生成的研究思路(问题、方法和实验设计)进行单独评估,这些标准如下图所示
最后,根据ReviewingAgents的审查和反馈,ResearchAgent进一步更新已生成的研究思路
值得一提的是,为了获得与人类对齐的评估标准,作者团队收集了每个评估标准上至少有3篇论文的人类研究人员对10对research idea及其分数(on a 5-point Likert scale)的标注「we first collect 10 pairs of the research idea and its score (on a 5-point Likert scale annotated by human researchers with at least 3 papers) on every evaluation criterion」
- 换言之,与基于模型的评估类似,进行人工评估,涉及为每个标准分配分数,并在10位专家注释者之间进行两两比较
Similar to model-based eval-uations, we perform human evaluations that involve assigning a score for each criterion and conduct-ing pairwise comparisons between two ideas, with 10 expert annotators
且,选择至少撰写了三篇论文的注释者,并要求他们评判从他们自己的论文中生成的想法
Thus, we choose annotators who have authored at least three papers and ask them to judge ideas that are generated from their own paper- 相当于在每个标准上,都会有三篇论文,然后由10个人类专家来针对论文提炼出来的问题(总计5个标准,每个标准上3篇论文,每篇论文10个分数)、方法、实验设计进行打分
1.2 实验部分
1.2.1 数据
生成研究思路的主要来源是科学文献 L,具体而言
- 首先,从Semantic Scholar Academic Graph API(https://www.semanticscholar.org/product/api)获取,且选择在2024年5月1日之后出版的论文
- 然后,我们选择具有超过20次引用的高影响力论文作为核心论文,以确保生成的思路具有高质量,这与人类研究人员倾向于利用有影响力的工作相一致
- 我们进一步随机抽取300篇论文作为核心论文(以获得一个合理大小的基准数据集),这意味着我们随后为每个模型生成和评估300个研究思路
其中,每篇核心论文的平均参考文献数量为87,每篇论文的摘要平均有2.17个实体
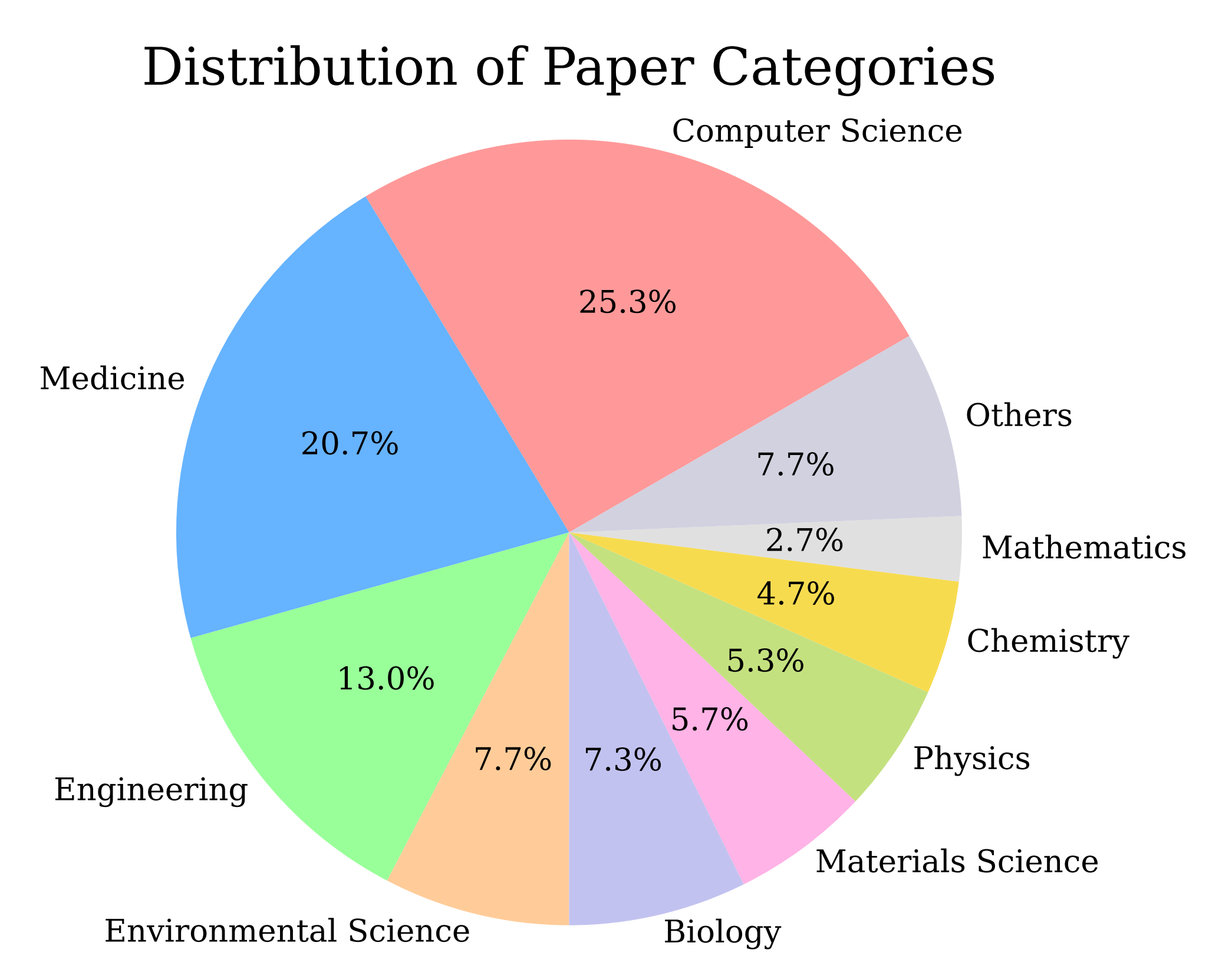
所有论文的学科分布如下图所示
1.2.2 几个对比标准与评估方法
由于我们的目标是研究思路的生成,因此没有直接可供比较的基线。 因此,完整的ResearchAgent模型与以下削弱版本进行比较:
- Naive ResearchAgent- 仅使用核心论文生成研究思路
- 没有实体检索的ResearchAgent- 使用核心论文及其相关参考文献,但不考虑实体
- ResearchAgent- 完整模型,使用相关参考文献和实体以及核心论文,以增强语言模型
基于模型的评估根据最近在使用LLMs评判输出文本质量方面的趋势(尤其是在无参考评估设置中),我们使用GPT-4来评判研究思路的质量
我们注意到,每个问题、方法和实验设计都使用五个不同的标准进行评估
然后,我们要求评估模型对每个标准上生成的思路进行on a 5-point Likert scale的评分,或者在不同模型的两个思路之间进行两两比较
// 待更
相关文章:
基于大模型的idea提炼:围绕论文和引用提炼idea之ResearchAgent
前言 对本博客比较熟悉的朋友知道,我司论文项目组正在基于大模型做论文的审稿(含CS英文论文审稿、和金融中文论文审稿)、翻译,且除了审稿翻译之外,我们还将继续做润色/修订、idea提炼(包含论文检索),是一个大的系统,包…...

前端深度扩展
1 为什么要有webpack 模块化管理:构建工具支持Common JS、ES6模块等规范;依赖管理:在大型项目中,手动管理文件依赖关系。webpack可以自动分析项目中的依赖关系,将其打包成1个或多个优化过的文件,减少页面加…...

雷军-2022.8小米创业思考-6-互联网七字诀之专注:有所为,有所不为;克制贪婪,少就是多;一次解决一个最迫切的需求
第六章 互联网七字诀 专注、极致、口碑、快,这就是我总结的互联网七字诀,也是我对互联网思维的高度概括。 专注 从商业角度看,专注就是要“把鸡蛋尽量放在一个篮子里”。这听起来似乎有些不合理,大家的第一反应可能是“风险会不会…...
【禅道客户案例】北大软件携手禅道,开启产品化之路新征程
在项目制项目模式下,软件公司根据客户的需求进行短期项目开发,具有灵活、高效、受众面广的优点,在业界得到了广泛的应用。但这种模式也面临诸多挑战,软件公司需要不断地开发新项目来维持业务增长,由于没有自己的产品也…...
解释泛型(Generics)在Java中的用途
在Java中,泛型(Generics)是一种在编译时期提供类型检查和约束的机制,它使得类和接口可以被参数化,即你可以定义一个类或接口,并通过参数传入具体的类型。泛型增加了代码的复用性和类型安全性,同…...

给网站网页PHP页面设置密码访问代码
将MkEncrypt.php文件上传至你网站根目录下或者同级目录下。 MkEncrypt.php里面添加代码,再将调用代码添加到你需要加密的页进行调用 MkEncrypt(‘123456’);括号里面123456修改成你需要设置的密码。 密码正确才能进去页面,进入后会存下cookies值&…...
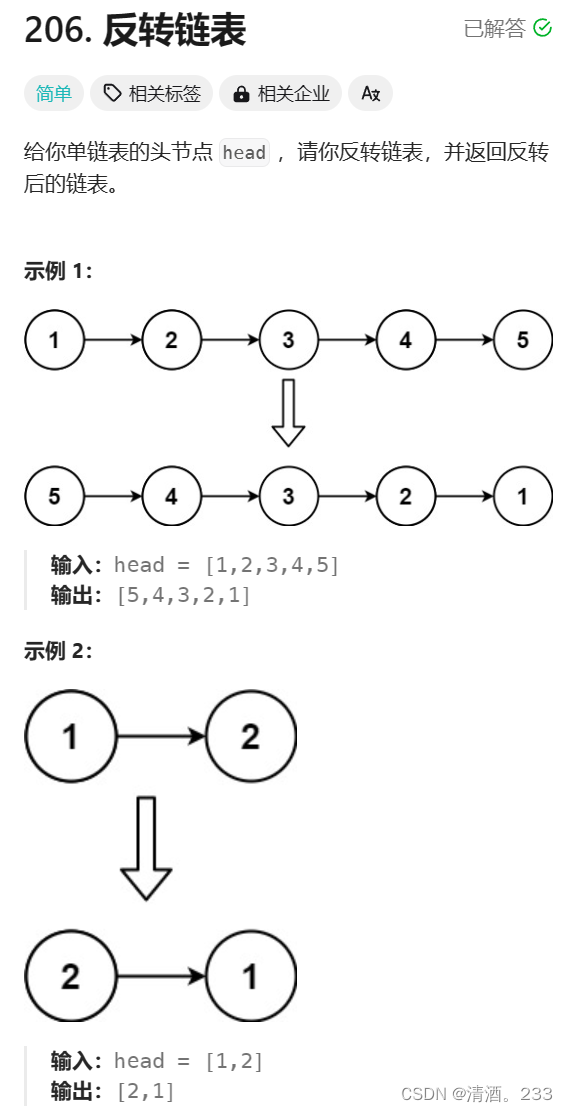
124.反转链表(力扣)
题目描述 代码解决(思路1:双指针) class Solution { public:ListNode* reverseList(ListNode* head) {ListNode*temp;//保存cur下一个节点ListNode*curhead;ListNode*preNULL;while(cur){tempcur->next;// 保存一下 cur的下一个节点&#…...
【数据库原理及应用】期末复习汇总高校期末真题试卷06
试卷 一、选择题 1. ________是长期存储在计算机内的有组织,可共享的数据集合. A.数据库管理系统 B.数据库系统 C.数据库 D.文件组织 1. 有12个实体类型,并且它们之间存在15个不同的二元联系,其中4个是1:1联系类型,5…...

Offline:IQL
ICLR 2022 Poster Intro 部分离线强化学习的对价值函数采用的是最小化均方bellman误差。而其中误差源自单步的TD误差。TD误差中对target Q的计算需要选取一个max的动作,这就容易导致采取了OOD的数据。因此,IQL取消max,,通过一个期望回归算子…...

图像涂哪就动哪!Gen-2新功能“神笔马良”爆火,网友:急急急
AI搞视频生成,已经进化到这个程度了?! 对着一张照片随手一刷,就能让被选中的目标动起来! 明明是一辆静止的卡车,一刷就跑了起来,连光影都完美还原: 原本只是一张火灾照片࿰…...

【管理篇】管理三步曲:任务执行(三)
目录标题 多任务并行如何应对?如何确保项目有效的执行项目执行过程中常见的问题1、目标不明确2、责任不明确3、流程不健全4、沟通不到位 如何有效执行任务 如何让流程机制有效的执行 研究任务管理,就是为了把事情做出来,产出实实在在的业绩和成果&#…...
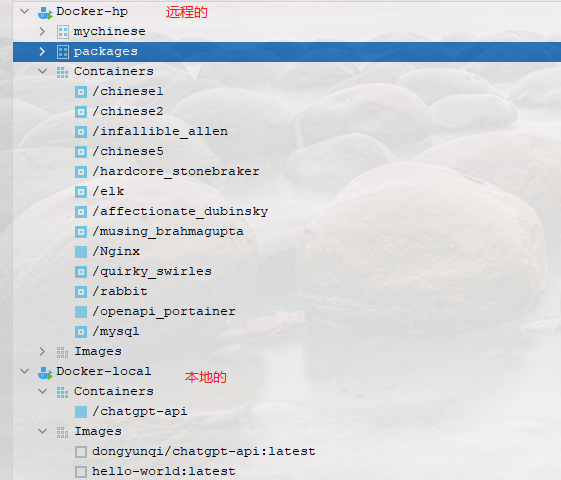
使用idea管理docker
写在前面 其实idea也提供了docker的管理功能,比如查看容器列表,启动容器,停止容器等,本文来看下如何管理本地的docker daemon和远程的dockers daemon。 1:管理本地 双击shift,录入service: …...
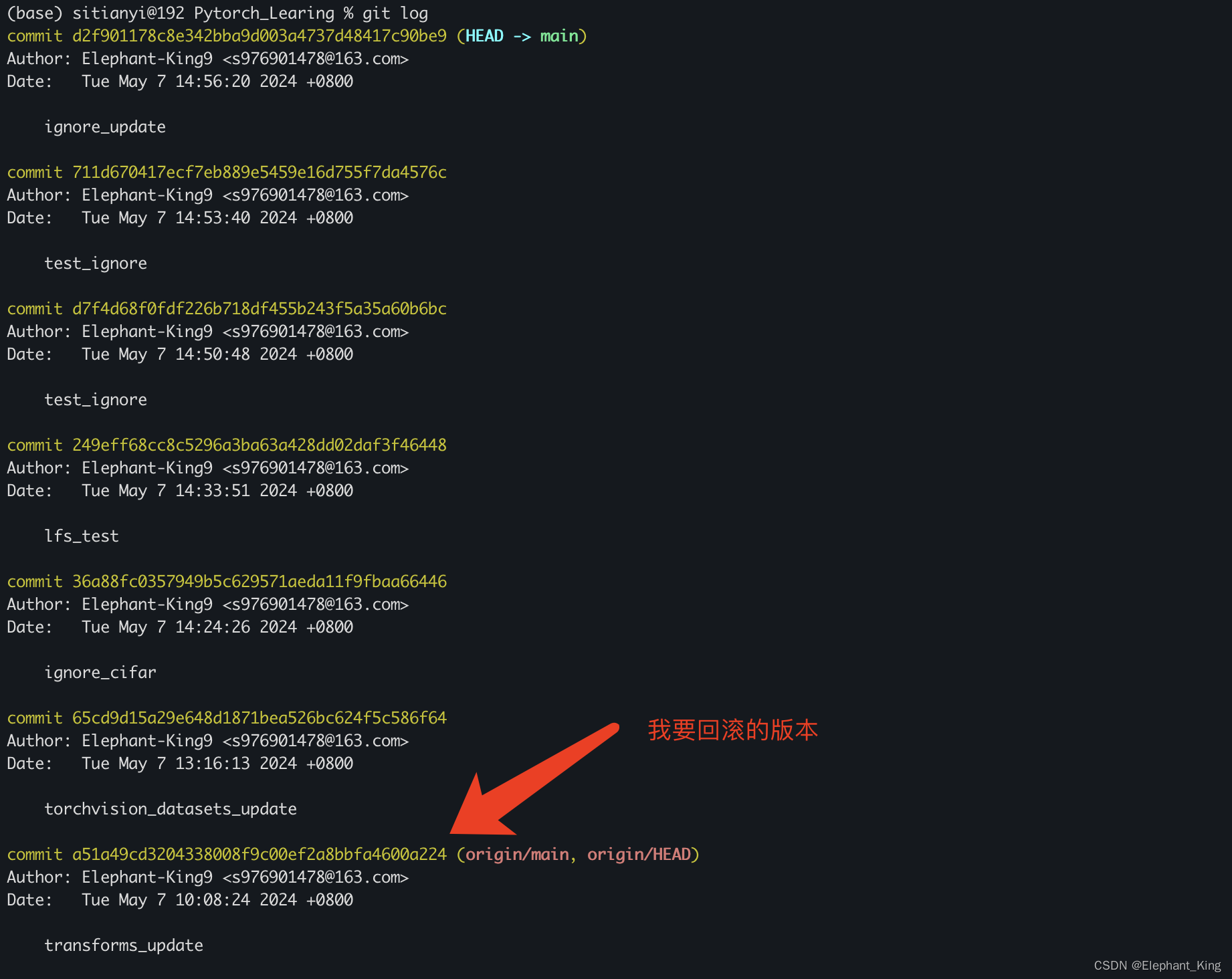
【Git】Commit后进行事务回滚
起因 因为一直使用git add .,在学习pytorch中添加了一个较大的数据集后,导致git push失败,而这个大数据集并不是必须要上传到仓库的,但是因为自己在设置.gitignore前已经进行了git comit,所以,需要进行事务…...
一分钟教你学浪app视频怎么缓存
你是否在学浪app上苦苦寻找如何缓存视频的方法?你是否想快速、轻松地观看自己喜欢的视频内容?那么,让我们一起探索一分钟教你如何缓存学浪app视频的技巧吧! 学浪下载工具我已经打包好了,有需要的自己下载一下 学浪下…...
stylus详解与引入
Stylus 是一个基于 Node.js 的 CSS 预处理器,它允许开发者以一种类似于脚本的方式编写 CSS 代码,从而创建出更加健壮、动态和富有表现力的样式表。Stylus 的特点包括: 1. 基于 JavaScript:由于 Node.js 是一个 JavaScript 运行环…...
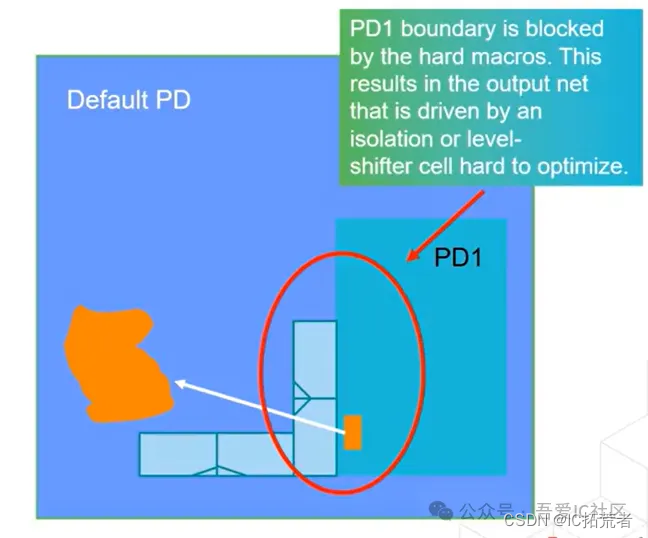
低功耗数字IC后端设计实现典型案例| UPF Flow如何避免工具乱用Always On Buffer?
下图所示为咱们社区低功耗四核A7 Top Hierarchical Flow后端训练营中的一个案例,设计中存在若干个Power Domain,其中Power Domain2(简称PD2)为default Top Domain,Power Domain1(简称PD1)为一个需要power off的domain&…...

前端 | 自定义电子木鱼
文章目录 📚实现效果📚模块实现解析🐇html🐇css🐇javascript 📚实现效果 📚模块实现解析 🐇html 搭个框架<!DOCTYPE html> <html lang"en"> <head>&l…...
Android4.4真机移植过程笔记(一)
1、RK源码编译 获取内核源码: git clone git172.28.1.172:rk3188_kernel -b xtc_ok1000 内核编译环境: 从172.28.1.132编译服务器的/data1/ZouZhiPing目录下拷贝toolchain.tar.gz(交叉编译工具链)并解压到与rk3188_kernel同级目…...
一觉醒来 AI科技圈发生的大小事儿 05月07日
📳从基因组到蛋白质组连续翻译,南开大学开发通用跨模态数据分析方法 南开大学的研究团队提出了scButterfly,一种基于双对齐变分自动编码器和数据增强方案的多功能单细胞跨模态翻译方法。该方法在保留细胞异质性、翻译各种背景数据集和揭示细…...

使用图网络和视频嵌入预测物理场
文章目录 一、说明二、为什么要预测?三、流体动力学模拟的可视化四、DeepMind神经网络建模五、图形编码六、图形处理器七、图形解码器八、具有不同弹簧常数的轨迹可视化九、预测的物理编码和推出轨迹 一、说明 这是一篇国外流体力学专家在可视化流体物理属性的设计…...

将java项目上传到GitHub步骤
文章目录 一、GitHub 作用二、github如何修改默认分支为master三、手把手教你把项目上传github上四、github怎么删除仓库或项目五、github配置ssh key密钥的步骤六、执行到push时报错的解决办法七、github怎么修改仓库语言 一、GitHub 作用 GitHub 是一个存放软件代码的网站&a…...

Electron项目中将CommonJS改成使用ES 模块(ESM)语法preload.js加载报错
问题 将Electron项目原CommonJS语法改成使用ES 模块(ESM)语法,preload.js一直加载不到,报错如下: VM111 renderer_init:2 Unable to load preload script: D:\Vue\wnpm\electron\preload.js VM111 renderer_init:2 E…...

Stable Diffusion 模型分享:Counterfeit-V3.0(动漫)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八 下载地址 模型介绍 高质量动漫风格模型。 条目内容类型大模型基础模…...
软件开发者如何保护自己的知识产权?
最近一个关于开源软件的知识产权纠纷的案例,非常有代表性, 其中涉及到的平台openwrt,一口君十几年前曾玩过, 通过这个案例,我们可以学习如何在今后工作中保护自己的知识产权, 以及如何合理直接或者间接利…...

Promise魔鬼面试题
文章目录 题目解析难点分析分析输出step1step2step3step4step5step6 参考/致谢:渡一袁老师 题目 Promise.resolve().then(() > {console.log(0);return Promise.resolve(4);}).then((res) > {console.log(res);});Promise.resolve().then(() > {console.l…...
Vue3+Nuxt3 从0到1搭建官网项目(SEO搜索、中英文切换、图片懒加载)
Vue2Nuxt2 从 0 到1 搭建官网~ Vue3Nuxt3 从0到1搭建官网项目 安装 Nuxt3,创建项目初始化的 package.json项目结构初始化项目pages 文件下创建index.vue引入sass修改 app.vue 文件查看效果 配置公共的css、metaassets下的cssreset.scss 重置文件common.scss 配置nux…...
面试经典150题——三数之和
面试经典150题 day29 题目来源我的题解方法一 暴力解法 超时方法二 扩展两数之和(双指针)方法三 扩展为通用的n数之和 题目来源 力扣每日一题;题序:15 我的题解 方法一 暴力解法 超时 进行三重循环遍历,判断和是否为…...
go动态创建/增加channel并处理数据
背景描述 有一个需求,大概可以描述为:有多个websocket连接,因此消息会并发地发送过来,这些消息中有一个标志可以表明是哪个连接发来的消息,但只有收到消息后才能建立channel或写入已有channel,在收消息前无…...
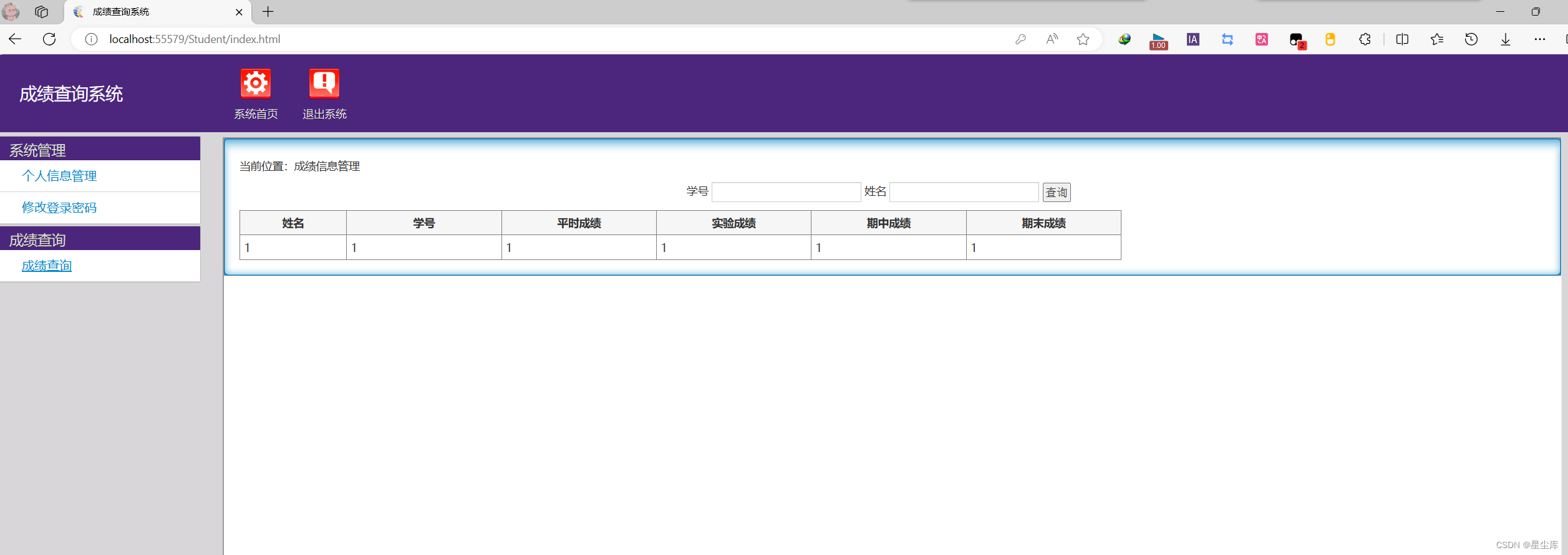
asp.net成绩查询系统
说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于asp.net架构和sql server数据库 功能模块: asp.net成绩查询系统 学生功能有查看成绩和修改账号密码等 后台管理员可以进行用户管理 管理员添加管理员查询注…...

Express路由
什么是路由 官方定义:路由确定了应用程序如何响应客户端对特定端点的请求。 路由的使用 一个路由的组成有 请求方法、路径 和 回调函数 组成。 Express中提供了一些列方法,可以很方便的使用路由,使用格式如下: app.<metho…...

在做题中学习(53): 寻找旋转数组中的最小值
153. 寻找旋转排序数组中的最小值 - 力扣(LeetCode) 解法:O(logn)->很可能就是二分查找 思路:再看看题目要求,可以画出旋转之后数组中元素的大小关系: 首先,数组是具有二段性的(适配二分查…...
C#语言进阶(三) 元组
总目录 C# 语法总目录 元组目录 元组1. 元组元素命名2. 元组的解构3. 元组的比较 元组 元组(tuple)是一组存储值的便捷方式。 元组的目的主要是,不使用out参数而从方法中返回多个值。(匿名类型无法做这个操作)元组能做匿名类型所有操作。 元组是值类型࿰…...
实用的Chrome 浏览器命令
Google Chrome 浏览器提供了许多快捷命令和实用功能,可以帮助用户提高效率和改善浏览体验。这里列举了一些非常实用的Chrome浏览器命令: 1. **CtrlT** / **CmdT** - 打开一个新的标签页。 2. **CtrlShiftT** / **CmdShiftT** - 重新打开最后关闭的标签页…...
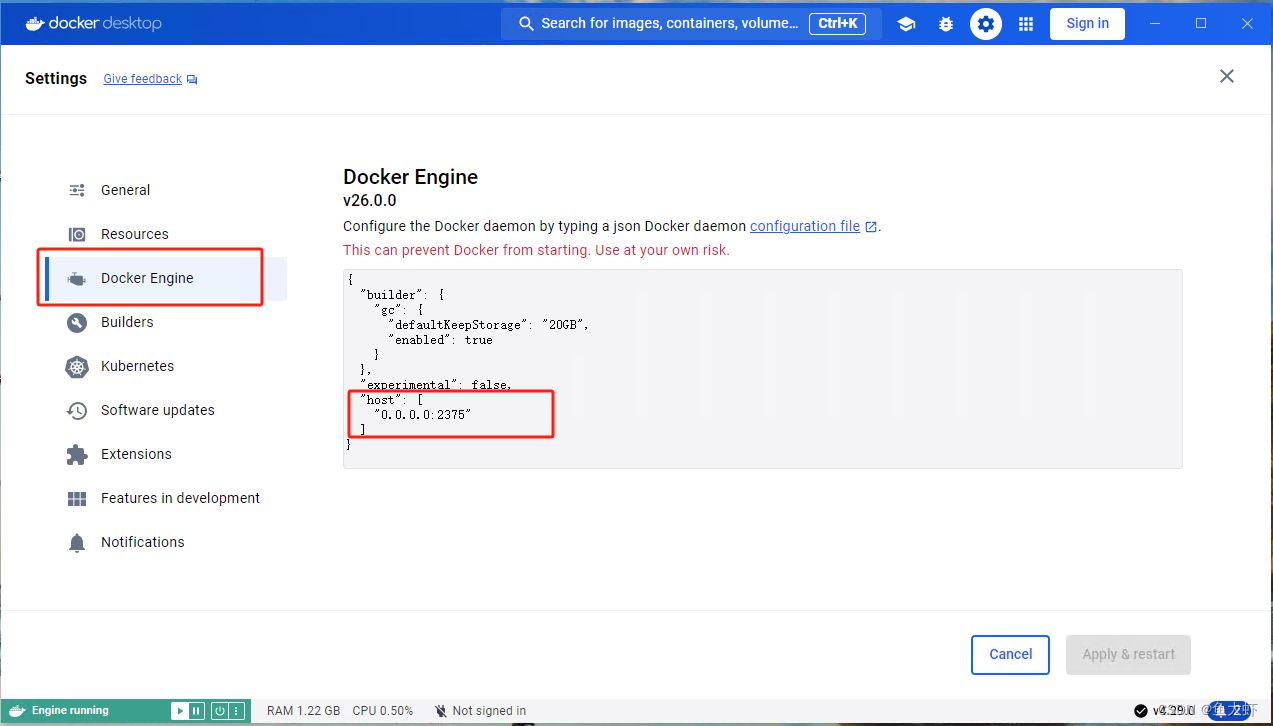
IDEA远程连接docker服务,windows版docker desktop
1.windows上安装docker desktop docker desktop下载地址:Docker Desktop: The #1 Containerization Tool for Developers | Docker 有的windows系统不支持安装docker desktop 安装完之后我们可以直接打开,可以选择不登录使用 我们用IDEA连接到docker …...
Rust 和 Go 哪个更好?
在讨论 Rust 与 Go 两种编程语言哪种更优秀时,我们将探讨它们在性能、简易性、安全性、功能、规模和并发处理等方面的比较。同时,我们看看它们有什么共同点和根本的差异。现在就来看看这个友好而公平的对比。 Rust 和 Go 都是优秀的选择 首先ÿ…...
【免费Java系列】大家好 ,今天是学习面向对象高级的第八天点赞收藏关注,持续更新作品 !
这是java进阶课面向对象第一天的课程可以坐传送去学习http://t.csdnimg.cn/Lq3io day08-Map集合、Stream流、File类 一、Map集合 同学们,在前面几节课我们已经学习了Map集合的常用方法,以及遍历方式。 下面我们要学习的是Map接口下面的是三个实现类H…...
RPC 失败。curl 16 Error in the HTTP2 framing layer
报错: (base) hh-virtual-machine:~/work$ git clone https://github.com/yangzongzhuan/RuoYi-Vue3.git 正克隆到 RuoYi-Vue3... error: RPC 失败。curl 16 Error in the HTTP2 framing layer fatal: 在引用列表之后应该有一个 flush 包这个错误通常是由于 Git 在…...
(图论)最短路问题合集(包含C,C++,Java,Python,Go)
不存在负权边: 1.朴素dijkstra算法 原题: 思路:(依然是贪心的思想) 1.初始化距离:dis[1]0,dis[i]INF(正无穷) 2.循环n次: 找到当前不在s中的dis最小的点&…...
电脑文件批量重命名不求人:快速操作,高效技巧让你轻松搞定
在数字化时代,电脑文件的管理与整理显得尤为重要。当面对大量需要重命名的文件时,一个个手动修改不仅耗时,还容易出错。那么,有没有一种方法可以快速、高效地完成这一任务呢?答案是肯定的,下面就来介绍几种…...
基于springboot的网上点餐系统源码数据库
基于springboot的网上点餐系统源码数据库 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于网上点餐系统当然也不能排除在外,随着网络技术的不断成熟,带动了网上点餐系统…...
mysql cluster数据库集群介绍、部署及配置
前言: MySQL集群是一个无共享的、分布式节点架构的存储方案,旨在提供容错性和高性能。它由三个主要节点组成:管理节点(MGM)、数据节点和SQL节点。 管理节点(MGM) 定义与用途:管理节点是MySQL Cluster的控制中心,负责管理集群内的其他节点。它提供配置数据,启动和停止…...

uniapp的app端软件更新弹框
1:使用html PLUS实现:地址HTML5 API Reference (html5plus.org),效果图 2:在app.vue的onLaunch生命周期中,代码如下: onLaunch: function() {let a 0let view new plus.nativeObj.View(maskView, {backg…...
win11 Terminal 部分窗口美化
需求及分析:因为在 cmd、anaconda prompt 窗口中输入命令较多,而命令输入行和输出结果都是同一个颜色,不易阅读,故将需求定性为「美化窗口」。 美化结束后,我在想是否能不安装任何软件,简单地通过调整主题颜…...
开源go实现的iot物联网新基建平台
软件介绍 Magistrala IoT平台是由Abstract Machines公司开发的创新基础设施解决方案,旨在帮助组织和开发者构建安全、可扩展和创新的物联网应用程序。曾经被称为Mainflux的平台,现在已经开源,并在国际物联网领域受到广泛关注。 功能描述 多协…...
24深圳杯ABCD成品论文47页+各小问代码+图表
A题多个火箭残骸的准确定位: A题已经更新完22页完整版论文+高清无水印照片+Python(MATLAB)代码简单麦麦https://www.jdmm.cc/file/2710544/ 问题1:单个残骸的音爆位置确定 建模思路: 1. 声波传…...

doris经典bug
在部署完登录web页面查看的时候会发现只有一个节点可以读取信息剩余的节点什么也没读取到 在发现问题后,我们去对应的节点去看log日志,发现它自己绑定到前端的地址上了 现在我们已经发现问题了,以下就开始解决问题 重置doris 首先对be进行操…...
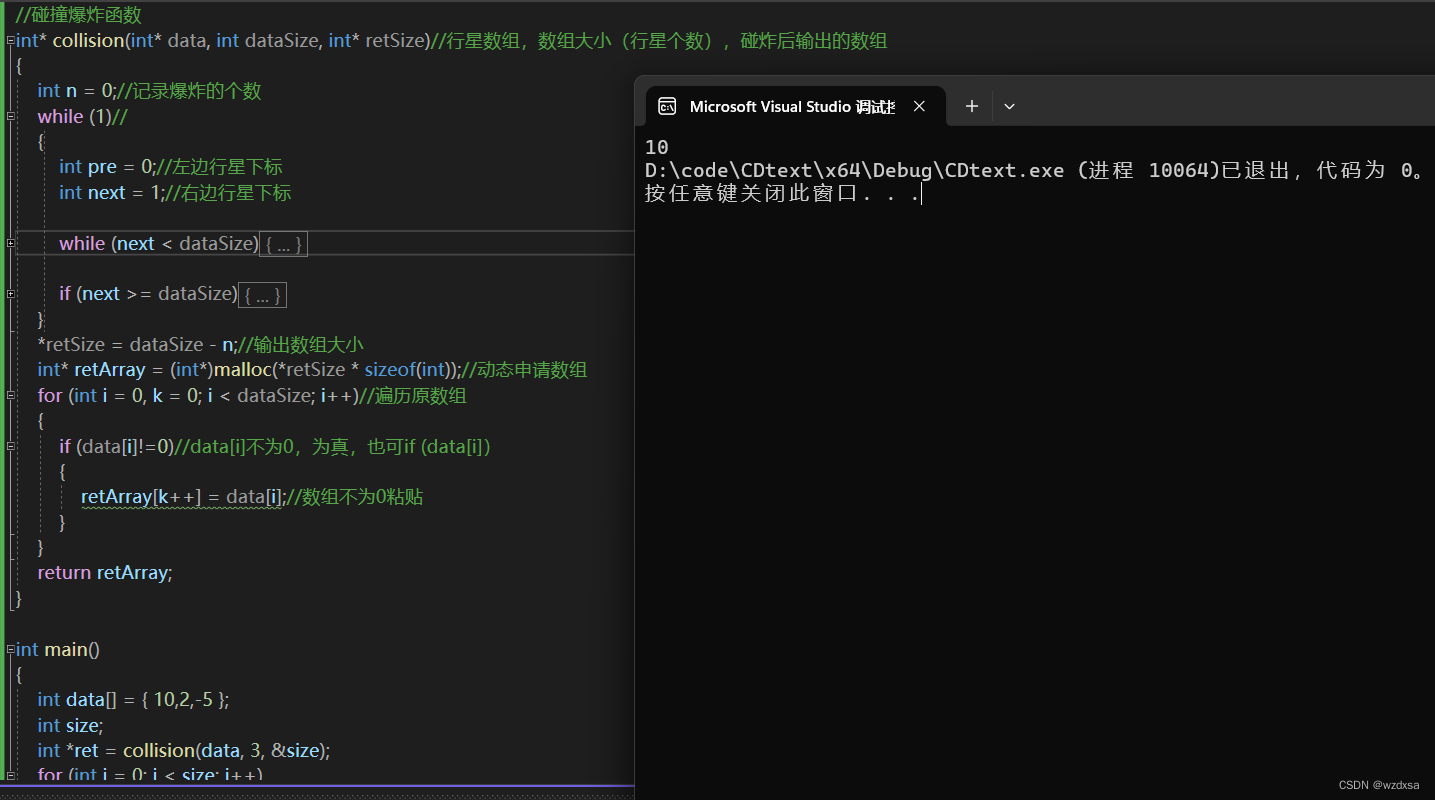
贪心算法应用例题
最优装载问题 #include <stdio.h> #include <algorithm>//排序int main() {int data[] { 8,20,5,80,3,420,14,330,70 };//物体重量int max 500;//船容最大总重量int count sizeof(data) / sizeof(data[0]);//物体数量std::sort(data, data count);//排序,排完数…...

亚信科技精彩亮相2024中国移动算力网络大会,数智创新共筑“新质生产力”
4月28至29日,江苏省人民政府指导、中国移动通信集团有限公司主办的2024中国移动算力网络大会在苏州举办。大会以“算力网络点亮AI时代”为主题,旨在凝聚生态伙伴合力,共同探索算力网络、云计算等数智能力空间,共促我国算网产业和数…...
图像处理中的颜色空间转换
在图像处理中,颜色空间转换是指将图像从一种颜色表示方式转换为另一种颜色表示方式。常见的颜色空间转换包括RGB到HSV、RGB到灰度、RGB到CMYK等。 RGB到HSV转换: RGB颜色空间由红色(R)、绿色(G)和蓝色&…...
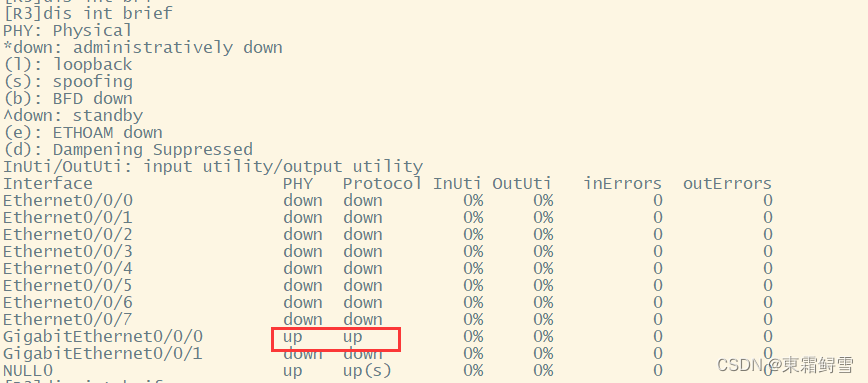
网络安全之静态路由
以下是一个静态路由的拓扑图 Aping通B,C可以ping通D。 路由器转发数据需要路由表,但仍可以Aping通B,C可以ping通D,是因为产生了直连路由:产生的条件有两个,接口有IP,接口双up(物理upÿ…...
记使用pdf.js过程遇到的坑
最近项目中需要用到js库来渲染pdf文件,调研后发现无论是reach-pdf.js或者是svelte-pdf.js都是在pdf.js基础上做了些许精简,反而功能还不如原始的pdf.js来得全面。但是原始的库几乎没有像样的代码示例,而能搜索到的大多数代码不少都是十几年前…...
PM入门必备| 怎么写产品分析报告?
小陪老师,产品经理是做些什么的呢?我去面试应该准备些什么呢? A: 首先要分清产品经理的类型,产品的面试需要准备的一般有Axure原型,需求文档,产品分析报告等,有些甚至需要展示项目经验。 tea…...
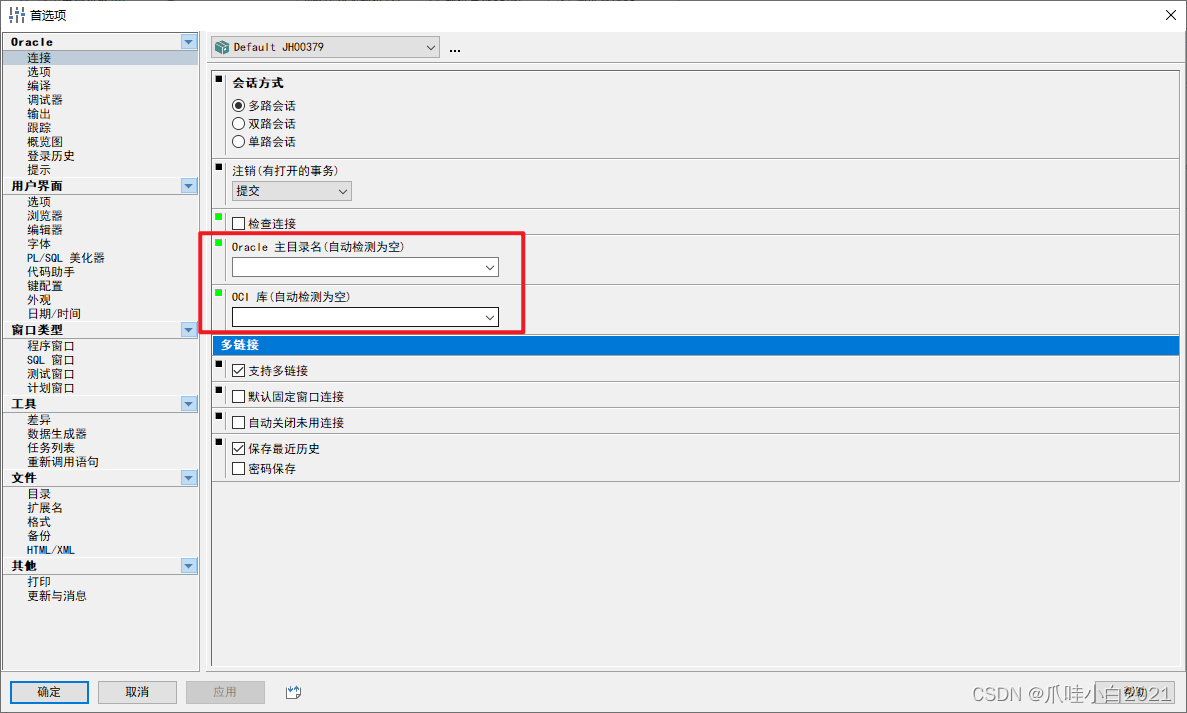
记PLSQL链接Oracle数据库
一、环境 Windows环境安装plsql工具 Oracle部署在服务器上面。 由于我之前在本地Windows安装了一个Oracle数据库,结果导致之前已经在连接的PLSQL链接不上。 二、操作 PLSQL工具正常安装,主要就是一些Oracle的一些配置,和oracle客户端。 o…...

用友GRP-U8 bx_dj_check.jsp SQL注入漏洞复现(XVE-2024-10537)
0x01 免责声明 请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任。工具来自网络,安全性自测,如有侵权请联系删…...
如何在WordPress中启用两因素身份验证?
在WordPress中启用两因素身份验证方法:安装和激活WordFence安全性、启用两因素验证。 使用您可以从任何位置登录的任何门户,建议启用两个因素身份验证以增加帐户的安全性。 这样,即使有人可以正确猜测你的密码,它们仍然需要获得2…...

没有疯狂内卷的日本智能机市场,小屏与设计仍旧是主流
如果聊起国内的智能机市场,我想大多数人的印象就是疯狂内卷。卷影像、卷屏幕、卷快充、卷性能……客观地说,国内的3C产品还是很有质价比的。不过在没有如此内卷的日本市场,各种小屏手机仍旧是主流。 除了苹果外,日本本土品牌的夏普…...