【免费Java系列】大家好 ,今天是学习面向对象高级的第八天点赞收藏关注,持续更新作品 !

这是java进阶课面向对象第一天的课程可以坐传送去学习http://t.csdnimg.cn/Lq3io
day08-Map集合、Stream流、File类
一、Map集合
同学们,在前面几节课我们已经学习了Map集合的常用方法,以及遍历方式。
下面我们要学习的是Map接口下面的是三个实现类HashMap、LinkedHashMap、TreeMap。实际上这三个实现类并没有什么特有方法需要我们学习,它们的方法就是前面学习Map的方法。这里我们主要学习它们的底层原理。
1.1 HashMap
首先,我们学习HashMap集合的底层原理。前面我们学习过HashSet的底层原理,实际上HashMap底层原理和HashSet是一样的。为什么这么说呢?因为我们往HashSet集合中添加元素时,实际上是把元素作为添加添加到了HashMap集合中。
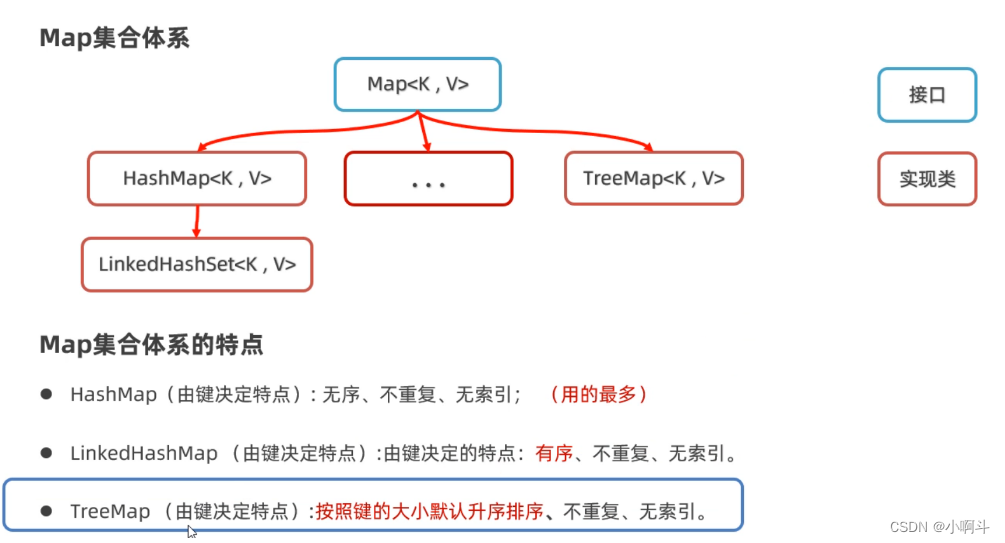
下面是Map集合的体系结构,HashMap集合的特点是由键决定的: 它的键是无序、不能重复,而且没有索引的。再各种Map集合中也是用得最多的一种集合。
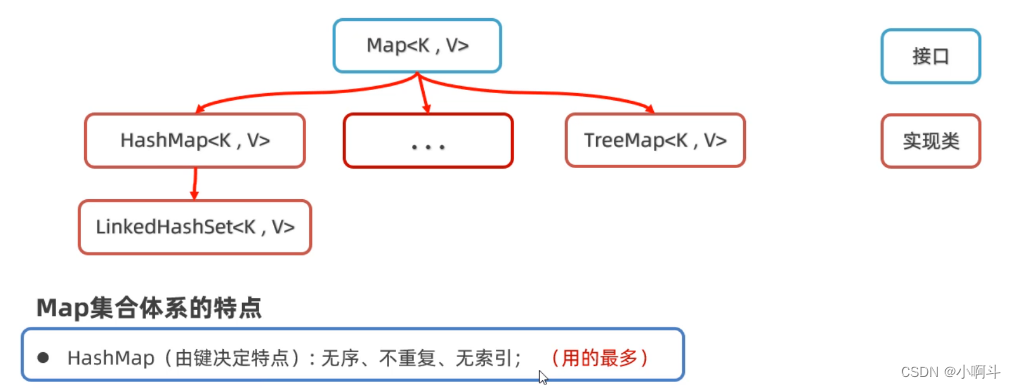
刚才我们说,HashSet底层就是HashMap,我们可以看源码验证这一点,如下图所示,我们可以看到,创建HashSet集合时,底层帮你创建了HashMap集合;往HashSet集合中添加添加元素时,底层却是调用了Map集合的put方法把元素作为了键来存储。所以实际上根本没有什么HashSet集合,把HashMap的集合的值忽略不看就是HashSet集合。

HashSet的原理我们之前已经学过了,所以HashMap是一样的,底层是哈希表结构。
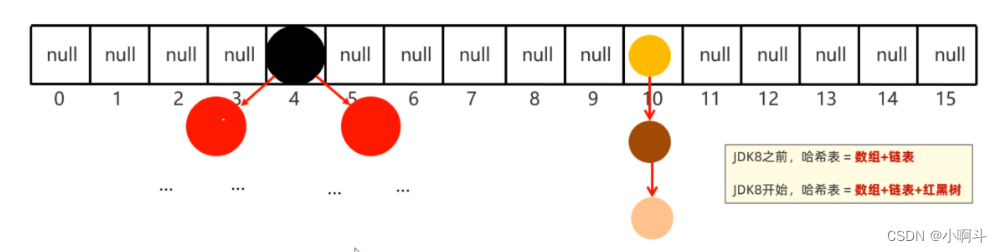
HashMap底层数据结构: 哈希表结构JDK8之前的哈希表 = 数组+链表JDK8之后的哈希表 = 数组+链表+红黑树哈希表是一种增删改查数据,性能相对都较好的数据结构往HashMap集合中键值对数据时,底层步骤如下第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组第2步:把键然后将键和值封装成一个对象,叫做Entry对象第3步:再根据Entry对象的键计算hashCode值(和值无关)第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置如果不为null,则还需要进行第6步的判断第6步:继续调用equals方法判断两个对象键是否相同如果equals返回false,则以链表的形式往下挂如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。HashMap底层需要注意这几点:1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍数组扩容的加载因子是0.75,意思是:16*0.75=12 2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储JDK7版本:链表采用头插法(新元素往链表的头部添加)JDK8版本:链表采用尾插法(新元素我那个链表的尾部添加)3.数组的同一个索引位置有多个元素、并且超过了8个,则以红黑树形式存储
从HashMap底层存储键值对的过程中我们发现:决定键是否重复依赖与两个方法,一个是hashCode方法、一个是equals方法。有两个键计算得到的hashCode值相同,并且两个键使用equals比较为true,就认为键重复。
所以,往Map集合中存储自定义对象作为键,为了保证键的唯一性,我们应该重写hashCode方法和equals方法。
比如有如下案例:往HashMap集合中存储Student对象作为键,学生的家庭住址当做值。要求,当学生对象的姓名和年龄相同时就认为键重复。
public class Student implements Comparable<Student> {private String name;private int age;private double height;
// this o@Overridepublic int compareTo(Student o) {return this.age - o.age; // 年龄升序排序}
@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);}
@Overridepublic int hashCode() {return Objects.hash(name, age, height);}
public Student() {}
public Student(String name, int age, double height) {this.name = name;this.age = age;this.height = height;}
//...get,set方法自己补全....
@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", height=" + height +'}';}
}写一个测试类,在测试类中,创建HashMap集合,键是Student类型,值是Stirng类型
/*** 目标:掌握Map集合下的实现类:HashMap集合的底层原理。*/
public class Test1HashMap {public static void main(String[] args) {Map<Student, String> map = new HashMap<>();map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}上面存储的键,有两个蜘蛛精,但是打印出只会有最后一个。

1.2 LinkedHashMap
学习完HashMap集合的特点,以及底层原理。接下来我们学习一下LinkedHashMap集合。
-
LinkedHashMap集合的特点也是由键决定的:有序的、不重复、无索引。
/*** 目标:掌握LinkedHashMap的底层原理。*/
public class Test2LinkedHashMap {public static void main(String[] args) {// Map<String, Integer> map = new HashMap<>(); // 按照键 无序,不重复,无索引。LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); // 按照键 有序,不重复,无索引。map.put("手表", 100);map.put("手表", 220);map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);}
}运行上面代码发现,如果是LinedHashMap集合键存储和取出的顺序是一样的

如果是HashMap,键存储和取出的顺序是不一致的
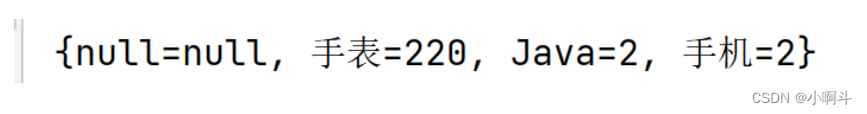
-
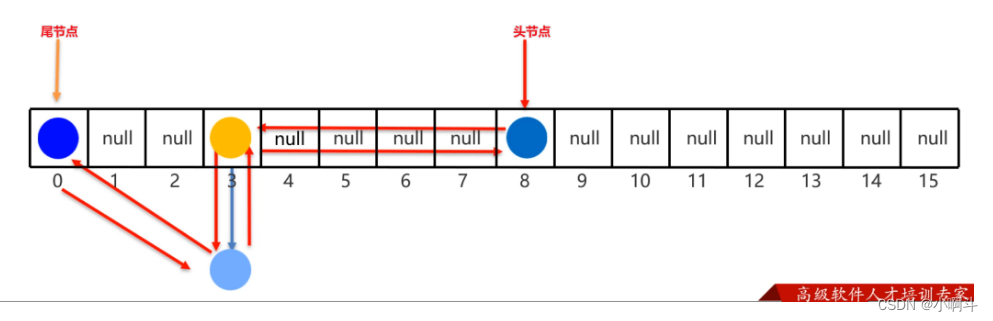
LinkedHashMap的底层原理,和LinkedHashSet底层原理是一样的。底层多个一个双向链表来维护键的存储顺序。
取元素时,先取头节点元素,然后再依次取下一个几点,一直到尾结点。所以是有序的。
1.3 TreeMap
最后,我们再学习Map集合下面的另一个子类叫TreeMap。根据我们前面学习其他Map集合的经验,我们应该可以猜出TreeMap有什么特点。
-
TreeMap集合的特点也是由键决定的,默认按照键的升序排列,键不重复,也是无索引的。
-
TreeMap集合的底层原理和TreeSet也是一样的,底层都是红黑树实现的。所以可以对键进行排序。
比如往TreeMap集合中存储Student对象作为键,排序方法有两种。直接看代码吧
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{private String name;private int age;private double height;//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。/*原理:在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的结果是正数、负数、还是零,决定元素放在后面、前面还是不存。*/@Overridepublic int compareTo(Student o) {//this:表示将要添加进去的Student对象//o: 表示集合中已有的Student对象return this.age-o.age;}
}排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/*** 目标:掌握TreeMap集合的使用。*/
public class Test3TreeMap {public static void main(String[] args) {Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return Double.compare(o1.getHeight(), o2.getHeight());}});
// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
1.4 集合嵌套
各位同学,到现在为止我们把Map集合和Collection集合的都已经学习完了。但是在实际开发中可能还会存在一种特殊的用法。就是把一个集合当做元素,存储到另一个集合中去,我们把这种用法称之为集合嵌套。
下面通过一个案例给大家演示一下

-
案例分析
1.从需求中我们可以看到,有三个省份,每一个省份有多个城市我们可以用一个Map集合的键表示省份名称,而值表示省份有哪些城市 2.而又因为一个身份有多个城市,同一个省份的多个城市可以再用一个List集合来存储。所以Map集合的键是String类型,而指是List集合类型HashMap<String, List<String>> map = new HashMap<>();
-
代码如下
/*** 目标:理解集合的嵌套。* 江苏省 = "南京市","扬州市","苏州市“,"无锡市","常州市"* 湖北省 = "武汉市","孝感市","十堰市","宜昌市","鄂州市"* 河北省 = "石家庄市","唐山市", "邢台市", "保定市", "张家口市"*/
public class Test {public static void main(String[] args) {// 1、定义一个Map集合存储全部的省份信息,和其对应的城市信息。Map<String, List<String>> map = new HashMap<>();
List<String> cities1 = new ArrayList<>();Collections.addAll(cities1, "南京市","扬州市","苏州市" ,"无锡市","常州市");map.put("江苏省", cities1);
List<String> cities2 = new ArrayList<>();Collections.addAll(cities2, "武汉市","孝感市","十堰市","宜昌市","鄂州市");map.put("湖北省", cities2);
List<String> cities3 = new ArrayList<>();Collections.addAll(cities3, "石家庄市","唐山市", "邢台市", "保定市", "张家口市");map.put("河北省", cities3);System.out.println(map);
List<String> cities = map.get("湖北省");for (String city : cities) {System.out.println(city);}
map.forEach((p, c) -> {System.out.println(p + "----->" + c);});}
}二、JDK8新特性(Stream流)
各位同学,接下来我们学习一个全新的知识,叫做Stream流(也叫Stream API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案例体验一下,然后再详细学习。
2.1 Stream流体验
案例需求:有一个List集合,元素有"张三丰","张无忌","周芷若","赵敏","张强",找出姓张,且是3个字的名字,存入到一个新集合中去。
List<String> names = new ArrayList<>();
Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");
System.out.println(names);-
用传统方式来做,代码是这样的
// 找出姓张,且是3个字的名字,存入到一个新集合中去。
List<String> list = new ArrayList<>();
for (String name : names) {if(name.startsWith("张") && name.length() == 3){list.add(name);}
}
System.out.println(list);-
用Stream流来做,代码是这样的(ps: 是不是想流水线一样,一句话就写完了)
List<String> list2 = names.stream().filter(s -> s.startsWith("张")).filter(a -> a.length()==3).collect(Collectors.toList());
System.out.println(list2);先不用知道这里面每一句话是什么意思,具体每一句话的含义,待会再一步步学习。现在只是体验一下。
学习Stream流我们接下来,会按照下面的步骤来学习。
2.2 Stream流的创建
好,接下来我们正式来学习Stream流。先来学习如何创建Stream流、或者叫获取Stream流。
主要掌握下面四点:1、如何获取List集合的Stream流?2、如何获取Set集合的Stream流?3、如何获取Map集合的Stream流?4、如何获取数组的Stream流?
直接上代码演示
/*** 目标:掌握Stream流的创建。*/
public class StreamTest2 {public static void main(String[] args) {// 1、如何获取List集合的Stream流?List<String> names = new ArrayList<>();Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");Stream<String> stream = names.stream();
// 2、如何获取Set集合的Stream流?Set<String> set = new HashSet<>();Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","马德","德玛西亚");Stream<String> stream1 = set.stream();stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));
// 3、如何获取Map集合的Stream流?Map<String, Double> map = new HashMap<>();map.put("古力娜扎", 172.3);map.put("迪丽热巴", 168.3);map.put("马尔扎哈", 166.3);map.put("卡尔扎巴", 168.3);
Set<String> keys = map.keySet();Stream<String> ks = keys.stream();
Collection<Double> values = map.values();Stream<Double> vs = values.stream();
Set<Map.Entry<String, Double>> entries = map.entrySet();Stream<Map.Entry<String, Double>> kvs = entries.stream();kvs.filter(e -> e.getKey().contains("巴")).forEach(e -> System.out.println(e.getKey()+ "-->" + e.getValue()));
// 4、如何获取数组的Stream流?String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"};Stream<String> s1 = Arrays.stream(names2);Stream<String> s2 = Stream.of(names2);}
}
2.3 Stream流中间方法
在上一节,我们学习了创建Stream流的方法。接下来我们再来学习,Stream流中间操作的方法。
中间方法指的是:调用完方法之后其结果是一个新的Stream流,于是可以继续调用方法,这样一来就可以支持链式编程(或者叫流式编程)。

话不多说,直接上代码演示
/*** 目标:掌握Stream流提供的常见中间方法。*/
public class StreamTest3 {public static void main(String[] args) {List<Double> scores = new ArrayList<>();Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0);// 需求1:找出成绩大于等于60分的数据,并升序后,再输出。scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));
List<Student> students = new ArrayList<>();Student s1 = new Student("蜘蛛精", 26, 172.5);Student s2 = new Student("蜘蛛精", 26, 172.5);Student s3 = new Student("紫霞", 23, 167.6);Student s4 = new Student("白晶晶", 25, 169.0);Student s5 = new Student("牛魔王", 35, 183.3);Student s6 = new Student("牛夫人", 34, 168.5);Collections.addAll(students, s1, s2, s3, s4, s5, s6);// 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出.students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30).sorted((o1, o2) -> o2.getAge() - o1.getAge()).forEach(s -> System.out.println(s));
// 需求3:取出身高最高的前3名学生,并输出。students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())).limit(3).forEach(System.out::println);System.out.println("-----------------------------------------------");
// 需求4:取出身高倒数的2名学生,并输出。 s1 s2 s3 s4 s5 s6students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())).skip(students.size() - 2).forEach(System.out::println);
// 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出。students.stream().filter(s -> s.getHeight() > 168).map(Student::getName).distinct().forEach(System.out::println);
// distinct去重复,自定义类型的对象(希望内容一样就认为重复,重写hashCode,equals)students.stream().filter(s -> s.getHeight() > 168).distinct().forEach(System.out::println);
Stream<String> st1 = Stream.of("张三", "李四");Stream<String> st2 = Stream.of("张三2", "李四2", "王五");Stream<String> allSt = Stream.concat(st1, st2);allSt.forEach(System.out::println);}
}2.5 Stream流终结方法
最后,我们再学习Stream流的终结方法。这些方法的特点是,调用完方法之后,其结果就不再是Stream流了,所以不支持链式编程。
我列举了下面的几个终结方法,接下来用几个案例来一个一个给同学们演示。
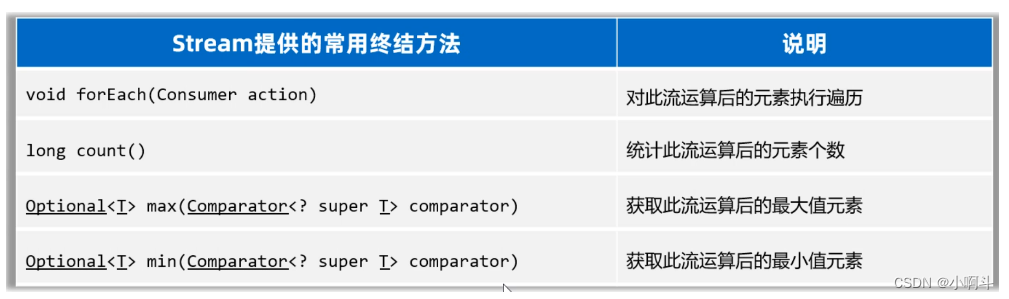
话不多说,直接上代码
/*** 目标:Stream流的终结方法*/
public class StreamTest4 {public static void main(String[] args) {List<Student> students = new ArrayList<>();Student s1 = new Student("蜘蛛精", 26, 172.5);Student s2 = new Student("蜘蛛精", 26, 172.5);Student s3 = new Student("紫霞", 23, 167.6);Student s4 = new Student("白晶晶", 25, 169.0);Student s5 = new Student("牛魔王", 35, 183.3);Student s6 = new Student("牛夫人", 34, 168.5);Collections.addAll(students, s1, s2, s3, s4, s5, s6);// 需求1:请计算出身高超过168的学生有几人。long size = students.stream().filter(s -> s.getHeight() > 168).count();System.out.println(size);
// 需求2:请找出身高最高的学生对象,并输出。Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();System.out.println(s);
// 需求3:请找出身高最矮的学生对象,并输出。Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();System.out.println(ss);
// 需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。// 流只能收集一次。List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toList());System.out.println(students1);
Set<Student> students2 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toSet());System.out.println(students2);
// 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。Map<String, Double> map =students.stream().filter(a -> a.getHeight() > 170).distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));System.out.println(map);
// Object[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray();Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]);System.out.println(Arrays.toString(arr));}
}到这里,关于Stream流的操常见操作我们就已经学习完了。当然Stream流还有一些其他的方法,同学们遇到了也可以自己再研究一下。
三、File类
接下来,我们要学习的知识是一个File类。但是在讲这个知识点之前,我想先和同学们聊点别的,聊完之后再回过来学习File你会更容易理解一些。
-
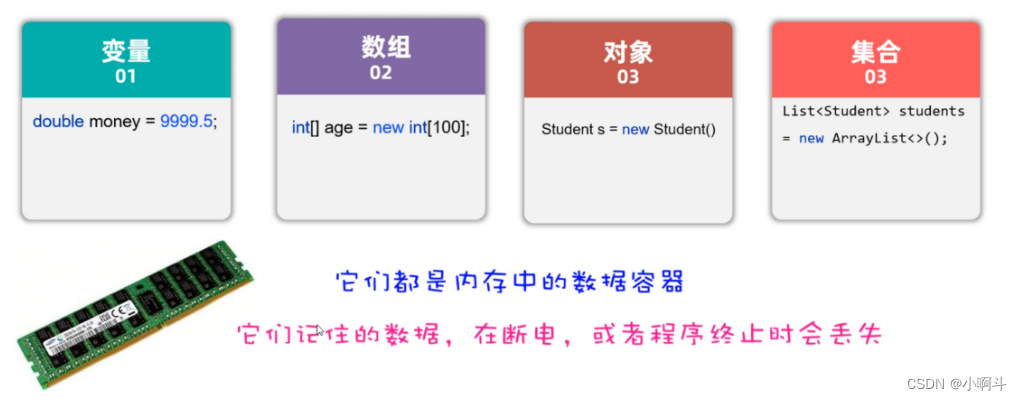
先问大家一个问题,目前你写代码时存储数据,可以用哪些方案?
答案如下图所示:可以是变量、可以是数组、可以是对象、可以是集合,但是这些数据都是存储在内存中的,只要程序执行结束,或者断点了,数据就消失了。不能永久存储。
-
有些数据要长久保存,该怎么办呢?
答案如下图所示:可以将数据以文件的形式存在硬盘里,即使程序结束了,断点了只要硬盘没坏,数据就永久存在。

而现在要学习的File类,它的就用来表示当前系统下的文件(也可以是文件夹),通过File类提供的方法可以获取文件大小、判断文件是否存在、创建文件、创建文件夹等。

但是需要我们注意:File对象只能对文件进行操作,不能操作文件中的内容。
3.1 File对象的创建
学习File类和其他类一样,第一步是创建File类的对象。 想要创建对象,我们得看File类有哪些构造方法。
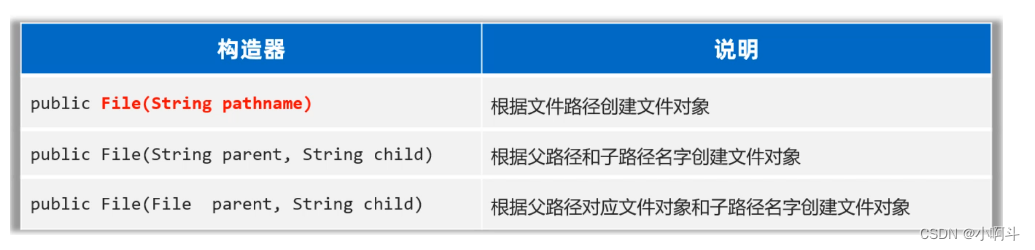
下面我们演示一下,File类创建对象的代码
需求我们注意的是:路径中"\"要写成"\\", 路径中"/"可以直接用
/*** 目标:掌握File创建对象,代表具体文件的方案。*/
public class FileTest1 {public static void main(String[] args) {// 1、创建一个File对象,指代某个具体的文件。// 路径分隔符// File f1 = new File("D:/resource/ab.txt");// File f1 = new File("D:\\resource\\ab.txt");File f1 = new File("D:" + File.separator +"resource" + File.separator + "ab.txt");System.out.println(f1.length()); // 文件大小
File f2 = new File("D:/resource");System.out.println(f2.length());
// 注意:File对象可以指代一个不存在的文件路径File f3 = new File("D:/resource/aaaa.txt");System.out.println(f3.length());System.out.println(f3.exists()); // false
// 我现在要定位的文件是在模块中,应该怎么定位呢?// 绝对路径:带盘符的// File f4 = new File("D:\\code\\javasepromax\\file-io-app\\src\\itheima.txt");// 相对路径(重点):不带盘符,默认是直接去工程下寻找文件的。File f4 = new File("file-io-app\\src\\itheima.txt");System.out.println(f4.length());}
}3.2 File判断和获取方法
各位同学,刚才我们创建File对象的时候,会传递一个文件路径过来。但是File对象封装的路径是存在还是不存在,是文件还是文件夹其实是不清楚的。好在File类提供了方法可以帮我们做判断。
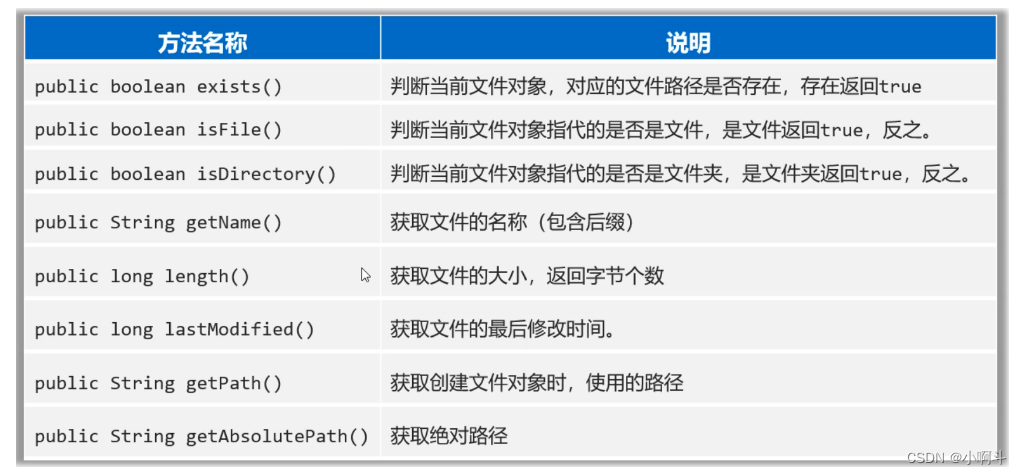
话不多少,直接上代码
/**目标:掌握File提供的判断文件类型、获取文件信息功能*/
public class FileTest2 {public static void main(String[] args) throws UnsupportedEncodingException {// 1.创建文件对象,指代某个文件File f1 = new File("D:/resource/ab.txt");//File f1 = new File("D:/resource/");
// 2、public boolean exists():判断当前文件对象,对应的文件路径是否存在,存在返回true.System.out.println(f1.exists());
// 3、public boolean isFile() : 判断当前文件对象指代的是否是文件,是文件返回true,反之。System.out.println(f1.isFile());
// 4、public boolean isDirectory() : 判断当前文件对象指代的是否是文件夹,是文件夹返回true,反之。System.out.println(f1.isDirectory());}
}除了判断功能还有一些获取功能,看代码
File f1 = new File("D:/resource/ab.txt");
// 5.public String getName():获取文件的名称(包含后缀)
System.out.println(f1.getName());
// 6.public long length():获取文件的大小,返回字节个数
System.out.println(f1.length());
// 7.public long lastModified():获取文件的最后修改时间。
long time = f1.lastModified();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
System.out.println(sdf.format(time));
// 8.public String getPath():获取创建文件对象时,使用的路径
File f2 = new File("D:\\resource\\ab.txt");
File f3 = new File("file-io-app\\src\\itheima.txt");
System.out.println(f2.getPath());
System.out.println(f3.getPath());
// 9.public String getAbsolutePath():获取绝对路径
System.out.println(f2.getAbsolutePath());
System.out.println(f3.getAbsolutePath());3.3 创建和删除方法
刚才有同学问老师,我们不能不用Java代码创建一个文件或者文件夹呀?答案是有的,不光可以创建还可以删除。
File类提供了创建和删除文件的方法,话不多少,看代码。
/*** 目标:掌握File创建和删除文件相关的方法。*/
public class FileTest3 {public static void main(String[] args) throws Exception {// 1、public boolean createNewFile():创建一个新文件(文件内容为空),创建成功返回true,反之。File f1 = new File("D:/resource/itheima2.txt");System.out.println(f1.createNewFile());
// 2、public boolean mkdir():用于创建文件夹,注意:只能创建一级文件夹File f2 = new File("D:/resource/aaa");System.out.println(f2.mkdir());
// 3、public boolean mkdirs():用于创建文件夹,注意:可以创建多级文件夹File f3 = new File("D:/resource/bbb/ccc/ddd/eee/fff/ggg");System.out.println(f3.mkdirs());
// 3、public boolean delete():删除文件,或者空文件,注意:不能删除非空文件夹。System.out.println(f1.delete());System.out.println(f2.delete());File f4 = new File("D:/resource");System.out.println(f4.delete());}
}需要注意的是:
1.mkdir(): 只能创建单级文件夹、 2.mkdirs(): 才能创建多级文件夹 3.delete(): 文件可以直接删除,但是文件夹只能删除空的文件夹,文件夹有内容删除不了。
3.4 遍历文件夹方法
有人说,想获取到一个文件夹中的内容,有没有方法呀?也是有的,下面我们就学习两个这样的方法。

话不多少上代码,演示一下
/*** 目标:掌握File提供的遍历文件夹的方法。*/
public class FileTest4 {public static void main(String[] args) {// 1、public String[] list():获取当前目录下所有的"一级文件名称"到一个字符串数组中去返回。File f1 = new File("D:\\course\\待研发内容");String[] names = f1.list();for (String name : names) {System.out.println(name);}
// 2、public File[] listFiles():(重点)获取当前目录下所有的"一级文件对象"到一个文件对象数组中去返回(重点)File[] files = f1.listFiles();for (File file : files) {System.out.println(file.getAbsolutePath());}
File f = new File("D:/resource/aaa");File[] files1 = f.listFiles();System.out.println(Arrays.toString(files1));}
}这里需要注意几个问题
1.当主调是文件时,或者路径不存在时,返回null 2.当主调是空文件夹时,返回一个长度为0的数组 3.当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹路径放在File数组中,并把数组返回 4.当主调是一个文件夹,且里面有隐藏文件时,将里面所有文件和文件夹的路径放在FIle数组中,包含隐藏文件 5.当主调是一个文件夹,但是没有权限访问时,返回null
关于遍历文件夹的基本操作就学习完了。 但是有同学如果想要获取文件夹中子文件夹的内容,那目前还做不到。但是学习下面了下面的递归知识就,很容易做到了。
四、递归
各位同学,为了获取文件夹中子文件夹的内容,我们就需要学习递归这个知识点。但是递归是什么意思,我们需要单独讲一下。学习完递归是什么,以及递归的执行流程之后,我们再回过头来用递归来找文件夹中子文件夹的内容。
4.1 递归算法引入
-
什么是递归?
递归是一种算法,从形式上来说,方法调用自己的形式称之为递归。
-
递归的形式:有直接递归、间接递归,如下面的代码。
/*** 目标:认识一下递归的形式。*/
public class RecursionTest1 {public static void main(String[] args) {test1();}
// 直接方法递归public static void test1(){System.out.println("----test1---");test1(); // 直接方法递归}
// 间接方法递归public static void test2(){System.out.println("---test2---");test3();}
public static void test3(){test2(); // 间接递归}
}
如果直接执行上面的代码,会进入死循环,最终导致栈内存溢出

以上只是用代码演示了一下,递归的形式。在下一节,在通过一个案例来给同学们讲一讲递归的执行流程。
4.2 递归算法的执行流程
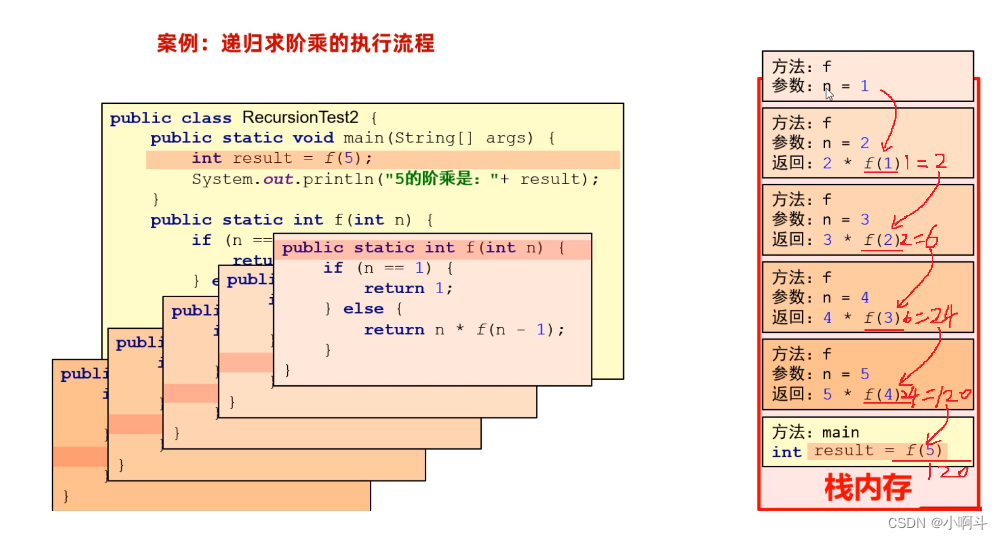
为了弄清楚递归的执行流程,接下来我们通过一个案例来学习一下。
案例需求:计算n的阶乘,比如5的阶乘 = 1 * 2 * 3 * 4 * 5 ; 6 的阶乘 = 1 * 2 * 3 * 4 * 5 * 6
分析需求用递归该怎么做
假设f(n)表示n的阶乘,那么我们可以推导出下面的式子f(5) = 1+2+3+4+5f(5) = f(4)+5f(4) = f(3)+4f(3) = f(2)+3f(2) = f(1)+2f(1) = 1 总结规律:除了f(1) = 1; 出口其他的f(n) = f(n-1)+n
我们可以把f(n)当做一个方法,那么方法的写法如下
/*** 目标:掌握递归的应用,执行流程和算法思想。*/
public class RecursionTest2 {public static void main(String[] args) {System.out.println("5的阶乘是:" + f(5));}
//求n个数的阶乘public static int f(int n){// 终结点if(n == 1){return 1;}else {return f(n - 1) * n;}}
}这个代码的执行流程,我们用内存图的形式来分析一下,该案例中递归调用的特点是:一层一层调用,再一层一层往回返。
4.3 递归文件搜索
学习完递归算法执行流程后,最后我们回过头来。再来看一下,如果使用递归来遍历文件夹。
案例需求:在D:\\判断下搜索QQ.exe这个文件,然后直接输出。
1.先调用文件夹的listFiles方法,获取文件夹的一级内容,得到一个数组 2.然后再遍历数组,获取数组中的File对象 3.因为File对象可能是文件也可能是文件夹,所以接下来就需要判断判断File对象如果是文件,就获取文件名,如果文件名是`QQ.exe`则打印,否则不打印判断File对象如果是文件夹,就递归执行1,2,3步骤 所以:把1,2,3步骤写成方法,递归调用即可。
代码如下:
/*** 目标:掌握文件搜索的实现。*/
public class RecursionTest3 {public static void main(String[] args) throws Exception {searchFile(new File("D:/") , "QQ.exe");}
/*** 去目录下搜索某个文件* @param dir 目录* @param fileName 要搜索的文件名称*/public static void searchFile(File dir, String fileName) throws Exception {// 1、把非法的情况都拦截住if(dir == null || !dir.exists() || dir.isFile()){return; // 代表无法搜索}
// 2、dir不是null,存在,一定是目录对象。// 获取当前目录下的全部一级文件对象。File[] files = dir.listFiles();
// 3、判断当前目录下是否存在一级文件对象,以及是否可以拿到一级文件对象。if(files != null && files.length > 0){// 4、遍历全部一级文件对象。for (File f : files) {// 5、判断文件是否是文件,还是文件夹if(f.isFile()){// 是文件,判断这个文件名是否是我们要找的if(f.getName().contains(fileName)){System.out.println("找到了:" + f.getAbsolutePath());Runtime runtime = Runtime.getRuntime();runtime.exec(f.getAbsolutePath());}}else {// 是文件夹,继续重复这个过程(递归)searchFile(f, fileName);}}}}
}今天的学习内容就到这啦 , 点点关注 , 明天见!!!
相关文章:
【免费Java系列】大家好 ,今天是学习面向对象高级的第八天点赞收藏关注,持续更新作品 !
这是java进阶课面向对象第一天的课程可以坐传送去学习http://t.csdnimg.cn/Lq3io day08-Map集合、Stream流、File类 一、Map集合 同学们,在前面几节课我们已经学习了Map集合的常用方法,以及遍历方式。 下面我们要学习的是Map接口下面的是三个实现类H…...

RPC 失败。curl 16 Error in the HTTP2 framing layer
报错: (base) hh-virtual-machine:~/work$ git clone https://github.com/yangzongzhuan/RuoYi-Vue3.git 正克隆到 RuoYi-Vue3... error: RPC 失败。curl 16 Error in the HTTP2 framing layer fatal: 在引用列表之后应该有一个 flush 包这个错误通常是由于 Git 在…...
(图论)最短路问题合集(包含C,C++,Java,Python,Go)
不存在负权边: 1.朴素dijkstra算法 原题: 思路:(依然是贪心的思想) 1.初始化距离:dis[1]0,dis[i]INF(正无穷) 2.循环n次: 找到当前不在s中的dis最小的点&…...
电脑文件批量重命名不求人:快速操作,高效技巧让你轻松搞定
在数字化时代,电脑文件的管理与整理显得尤为重要。当面对大量需要重命名的文件时,一个个手动修改不仅耗时,还容易出错。那么,有没有一种方法可以快速、高效地完成这一任务呢?答案是肯定的,下面就来介绍几种…...
基于springboot的网上点餐系统源码数据库
基于springboot的网上点餐系统源码数据库 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于网上点餐系统当然也不能排除在外,随着网络技术的不断成熟,带动了网上点餐系统…...
mysql cluster数据库集群介绍、部署及配置
前言: MySQL集群是一个无共享的、分布式节点架构的存储方案,旨在提供容错性和高性能。它由三个主要节点组成:管理节点(MGM)、数据节点和SQL节点。 管理节点(MGM) 定义与用途:管理节点是MySQL Cluster的控制中心,负责管理集群内的其他节点。它提供配置数据,启动和停止…...

uniapp的app端软件更新弹框
1:使用html PLUS实现:地址HTML5 API Reference (html5plus.org),效果图 2:在app.vue的onLaunch生命周期中,代码如下: onLaunch: function() {let a 0let view new plus.nativeObj.View(maskView, {backg…...
win11 Terminal 部分窗口美化
需求及分析:因为在 cmd、anaconda prompt 窗口中输入命令较多,而命令输入行和输出结果都是同一个颜色,不易阅读,故将需求定性为「美化窗口」。 美化结束后,我在想是否能不安装任何软件,简单地通过调整主题颜…...
开源go实现的iot物联网新基建平台
软件介绍 Magistrala IoT平台是由Abstract Machines公司开发的创新基础设施解决方案,旨在帮助组织和开发者构建安全、可扩展和创新的物联网应用程序。曾经被称为Mainflux的平台,现在已经开源,并在国际物联网领域受到广泛关注。 功能描述 多协…...
24深圳杯ABCD成品论文47页+各小问代码+图表
A题多个火箭残骸的准确定位: A题已经更新完22页完整版论文+高清无水印照片+Python(MATLAB)代码简单麦麦https://www.jdmm.cc/file/2710544/ 问题1:单个残骸的音爆位置确定 建模思路: 1. 声波传…...

doris经典bug
在部署完登录web页面查看的时候会发现只有一个节点可以读取信息剩余的节点什么也没读取到 在发现问题后,我们去对应的节点去看log日志,发现它自己绑定到前端的地址上了 现在我们已经发现问题了,以下就开始解决问题 重置doris 首先对be进行操…...
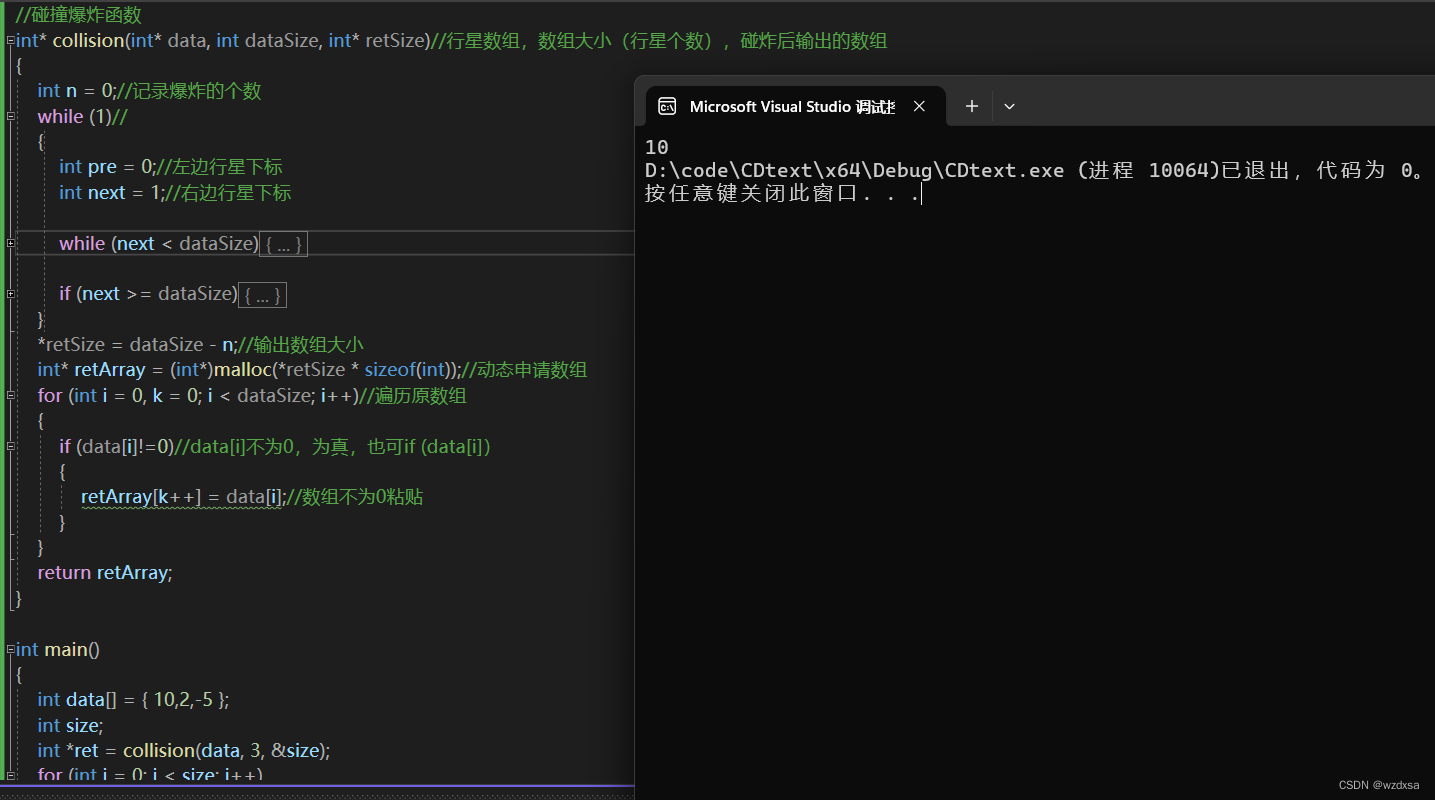
贪心算法应用例题
最优装载问题 #include <stdio.h> #include <algorithm>//排序int main() {int data[] { 8,20,5,80,3,420,14,330,70 };//物体重量int max 500;//船容最大总重量int count sizeof(data) / sizeof(data[0]);//物体数量std::sort(data, data count);//排序,排完数…...

亚信科技精彩亮相2024中国移动算力网络大会,数智创新共筑“新质生产力”
4月28至29日,江苏省人民政府指导、中国移动通信集团有限公司主办的2024中国移动算力网络大会在苏州举办。大会以“算力网络点亮AI时代”为主题,旨在凝聚生态伙伴合力,共同探索算力网络、云计算等数智能力空间,共促我国算网产业和数…...
图像处理中的颜色空间转换
在图像处理中,颜色空间转换是指将图像从一种颜色表示方式转换为另一种颜色表示方式。常见的颜色空间转换包括RGB到HSV、RGB到灰度、RGB到CMYK等。 RGB到HSV转换: RGB颜色空间由红色(R)、绿色(G)和蓝色&…...
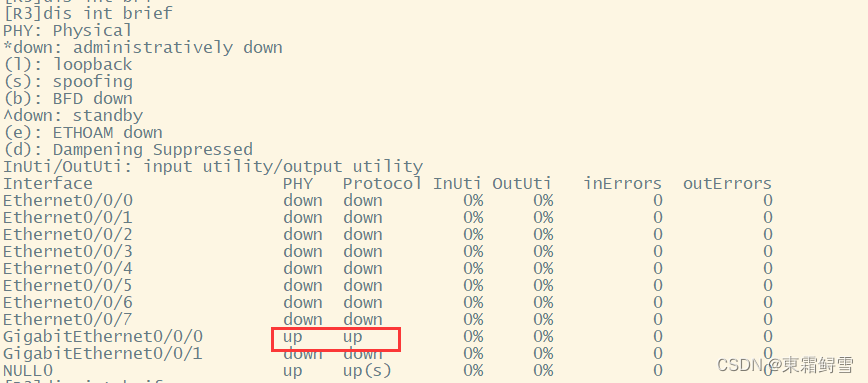
网络安全之静态路由
以下是一个静态路由的拓扑图 Aping通B,C可以ping通D。 路由器转发数据需要路由表,但仍可以Aping通B,C可以ping通D,是因为产生了直连路由:产生的条件有两个,接口有IP,接口双up(物理upÿ…...

Golang | Leetcode Golang题解之第74题搜索二维矩阵
题目: 题解: func searchMatrix(matrix [][]int, target int) bool {m, n : len(matrix), len(matrix[0])i : sort.Search(m*n, func(i int) bool { return matrix[i/n][i%n] > target })return i < m*n && matrix[i/n][i%n] target }...

2023黑马头条.微服务项目.跟学笔记(五)
2023黑马头条.微服务项目.跟学笔记 五 延迟任务精准发布文章 1.文章定时发布2.延迟任务概述 2.1 什么是延迟任务2.2 技术对比 2.2.1 DelayQueue2.2.2 RabbitMQ实现延迟任务2.2.3 redis实现3.redis实现延迟任务4.延迟任务服务实现 4.1 搭建heima-leadnews-schedule模块4.2 数据库…...

C语言 | Leetcode C语言题解之第75题颜色分类
题目: 题解: void swap(int *a, int *b) {int t *a;*a *b, *b t; }void sortColors(int *nums, int numsSize) {int p0 0, p2 numsSize - 1;for (int i 0; i < p2; i) {while (i < p2 && nums[i] 2) {swap(&nums[i], &num…...

淘宝扭蛋机小程序开发:掌上惊喜,转出你的幸运宝藏
一、全新玩法,尽在掌中 淘宝扭蛋机小程序,将传统的扭蛋乐趣与数字时代完美结合,为您带来全新的购物体验。在这个小小的平台上,您可以用手指轻松操控,探索无尽的宝藏世界,转出专属于您的幸运好物。 二、海…...

Oracle索引组织表与大对象平滑迁移至OceanBase的实施方案
作者简介:严军(花名吉远),十年以上专注于数据库存储领域,精通Oracle、Mysql、OceanBase,对大数据、分布式、高并发、高性能、高可用有丰富的经验。主导过蚂蚁集团核心系统数据库升级,数据库LDC单元化多活项目ÿ…...
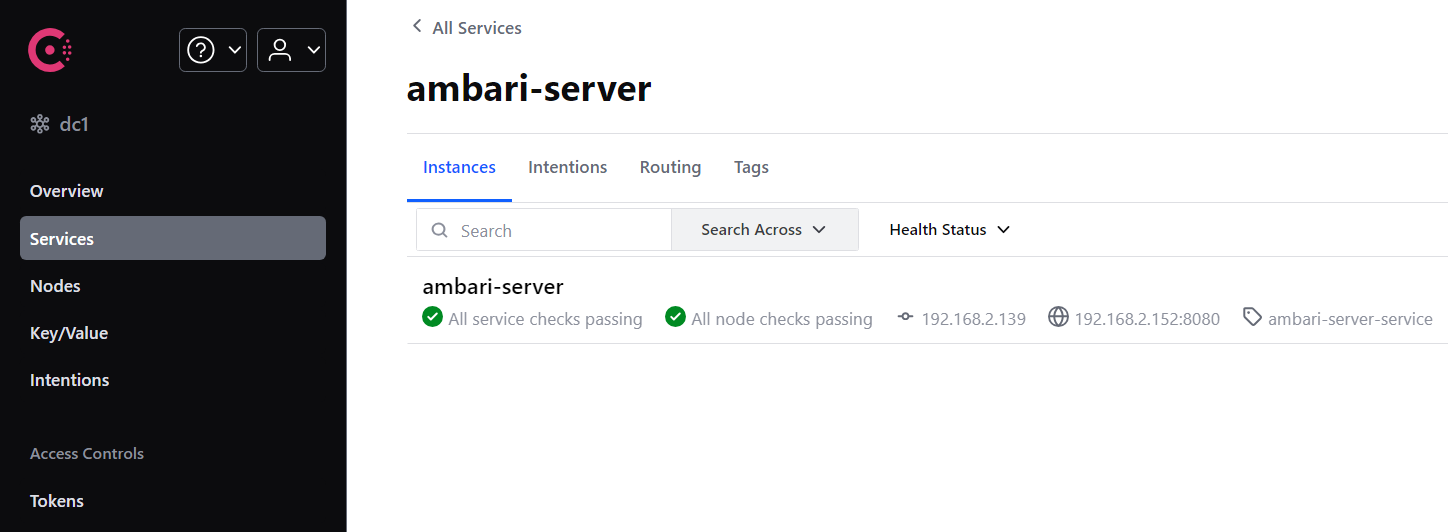
【服务治理中间件】consul介绍和基本原理
目录 一、CAP定理 二、服务注册中心产品比较 三、Consul概述 3.1 什么是Consul 3.2 Consul架构 3.3 Consul的使用场景 3.4 Consul健康检查 四、部署consul集群 4.1 服务器部署规划 4.2 下载解压 4.3 启动consul 五、服务注册到consul 一、CAP定理 CAP定理ÿ…...

无人机运营合格证:民用无人机驾驶航空器运营合格证书
无人机运营合格证是指经国家相关部门审核通过并颁发给相应无人驾驶航空器运营机构的一种资质证明。获得该证书的机构具备相关的技术和管理能力,能够安全、合规地运营无人驾驶航空器。 无人机运营合格证的申请流程一般包括报名、培训学习、考试准备、考试报名、考试…...

【编码利器 —— BaiduComate】
目录 1. 智能编码助手介绍 2. 场景需求 3. 功能体验 3.1指令功能 3.2插件用法 3.3知识用法 3.4自定义配置 4. 试用感受 5. AI编程应用 6.总结 智能编码助手是当下人工智能技术在编程领域的一项重要应用。Baidu Comate智能编码助手作为一款具有强大功能和智能特性的工…...
python 关键字(in)
9、in 在Python中,in关键字是一个强大的工具,用于检查一个元素是否存在于某个序列(如列表、元组、字符串等)或集合(如集合、字典的键)中。 基础小白知识:in的基本用法 1.1 在序列中检查元素 …...
【Node.js从基础到高级运用】二十八、Node.js 内存管理浅析
Node.js 作为一个基于 Chrome V8 引擎的 JavaScript 运行环境,其性能和效率在很大程度上取决于内存管理的优劣。 1. Node.js 内存结构 在深入了解内存管理之前,我们需要先了解 Node.js 的内存结构。Node.js 的内存可以大致分为以下几个部分:…...
AES加密解密
加密 java.util.Base64; javax.crypto.Cipher; javax.crypto.spec.SecretKeySpec; // 入参:data(String)、seed(String) Cipher cipher Cipher.getInstance("AES/ECB/PKCS5Padding"); SecretKeySpec secre…...

通过红黑树封装 map 和 set 容器(1):红黑树的迭代器
一、红黑树的迭代器 红黑树的遍历默认为中序遍历 —— key 从小到大,因此 begin() 应该获取到红黑树的最左节点 —— 最小,end() 获取到红黑树最右节点的下一个位置, operator() 也应保证红黑树的遍历为中序的状态。 首先对红黑树节点进行改造…...
mysqlbinlog恢复delete的数据
实验目的 delete数据后,用mysqlbinlog进行数据恢复 实验过程 原表 mysql> select * from mytest; ----------------- | id | name | score | ----------------- | 1 | xw01 | 90 | | 2 | xw02 | 92 | | 3 | xw03 | 93 | | 4 | xw04 | 94 | |…...
传递给组件
React 组件使用 props 相互通信。每个父组件都可以通过为其子组件提供道具来将一些信息传递给子组件。Props 可能会让您想起 HTML 属性,但您可以通过它们传递任何 JavaScript 值,包括对象、数组和函数。 Props 是传递给 JSX 标签的信息。例如࿰…...

鸿蒙通用组件弹窗简介
鸿蒙通用组件弹窗简介 弹窗----Toast引入ohos.promptAction模块通过点击按钮,模拟弹窗 警告对话框----AlertDialog列表弹窗----ActionSheet选择器弹窗自定义弹窗使用CustomDialog声明一个自定义弹窗在需要使用的地方声明自定义弹窗,完整代码 弹窗----Toa…...

[译文] 恶意代码分析:1.您记事本中的内容是什么?受感染的文本编辑器notepad++
这是作者新开的一个专栏,主要翻译国外知名安全厂商的技术报告和安全技术,了解它们的前沿技术,学习它们威胁溯源和恶意代码分析的方法,希望对您有所帮助。当然,由于作者英语有限,会借助LLM进行校验和润色&am…...
Spring Boot3.x集成Disruptor4.0
Disruptor介绍 Disruptor是一个高性能内存队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年&…...

GoEdge自建CDN工具
GoEdge是一款管理分布式CDN边缘节点的开源工具软件,可以让用户轻松地、低成本地创建CDN/WAF等应用。同时提供免费版本和商业版本,本文基本免费版本安装测试。 GoEdgep安装涉及三部分: 边缘节点 - 接收和响应用户请求的终端节点 管理员系统 - …...
牛客储物点的距离
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 一个数轴,每一个储物点会有一些东西,同时它们之间存在距离。 每次给个区间[l,r],查询把这个区间内所有储物点的东西运到另外一个储物点的代价是多少࿱…...

【C++历练之路】红黑树——map与set的封装实现
W...Y的个人主页💕 gitee代码仓库分享😊 前言:上篇博客中,我们为了使二叉搜索树不会出现”一边倒“的情况,使用了AVL树对搜索树进行了处理,从而解决了数据在有序或者接近有序时出现的情况。但是AVL树还会…...
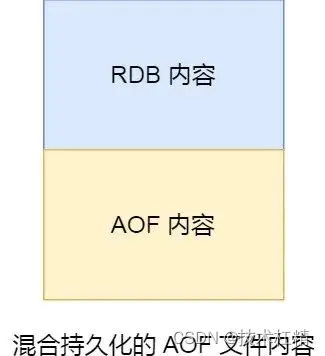
RDB快照是怎么实现的?
RDB快照是怎么实现的? 前言快照怎么用?执行快照时,数据能被修改吗?RDB 和 AOF 合体 前言 虽说 Redis 是内存数据库,但是它为数据的持久化提供了两个技术。 分别是「 AOF 日志和 RDB 快照」。 这两种技术都会用各用一…...
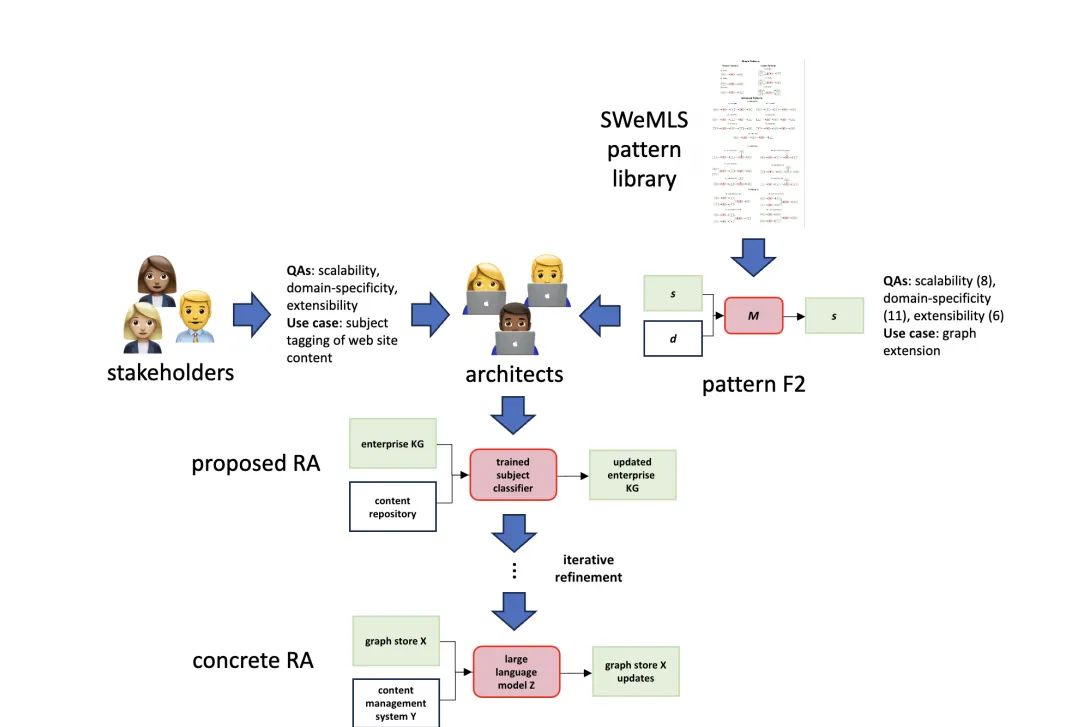
智能体可靠性的革命性提升,揭秘知识工程领域的参考架构新篇章
引言:知识工程的演变与重要性 知识工程(Knowledge Engineering,KE)是一个涉及激发、捕获、概念化和形式化知识以用于信息系统的过程。自计算机科学和人工智能(AI)历史以来,知识工程的工作流程因…...
Shell 初始化配置指北 | Ubuntu
唠唠闲话 概要:在不同的Shell环境(如Bash和Zsh)中设置环境变量、设置初始脚本,以及如何根据不同的使用场景(用户级或系统级)管理和设置初始运行命令。 p.s. 如果你很熟悉 Linux,推荐跳到最后一…...
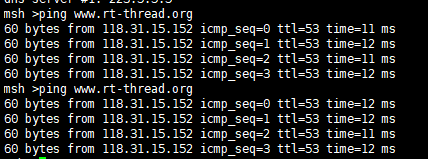
[嵌入式系统-69]:RT-Thread-组件:网络组件“组”,RT-Thread系统通向外部网络世界的入口
目录 RT-Thread 提供的网络世界入口 - 网络组件 1. 总概 2. AT 3. Lwip: 轻量级IP协议栈 4. W5500 5. Netdev 6. RT-Thread SAL(Socket Abstraction Layer)套接字和BSD套接字区别 RT-Thread SAL 套接字接口示例 BSD 套接字接口示例 …...

Linux学习笔记1---Windows上运行Linux
在正点原子的教程中学习linux需要安装虚拟机或者在电脑上安装一个Ubuntu系统,但个人觉得太麻烦了,现在linux之父加入了微软,因此在Windows上也可以运行linux 了。具体方法如下: 一、 在Windows上的设置 在window的搜索框内&#…...
Java算法-力扣leetcode-135. 分发糖果
135. 分发糖果 n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩子分发糖果,计算并…...
企业为什么需要主数据管理工具?十大热门主数据管理工具盘点
主数据管理是一套综合性的策略和技术,用于协调和管理企业内用于识别关键业务实体(如客户、产品、供应商和员工)的一致性、准确性和统一性的数据。主数据管理的目的是创建一个“单一真相源”,确保在不同部门和系统之间共享的数据保…...

免费思维13招之一:体验型思维
思维01:体验型思维 第一大战略:体验型思维。 体验型思维是免费思维中最简单的思维,我们先从最简单的讲起,由简入繁,简单的我们少讲,复杂的我们多讲。 那么,什么是体验型思维呢? 很简单,就是先让客户进行体验,再进行成交的方式。这一种思维,具体的可以分为两种:…...

面试C++(基础篇)-NULL与nullptr的区别?
3: NULL与nullptr的区别? 在C中,NULL和nullptr都用于表示空指针,但它们之间存在一些关键的区别: 1. 来源和含义: • NULL:在C中,NULL最初是从C语言中继承过来的,定义在<cstddef…...
「AIGC」深度学习
深度学习是机器学习的一个子领域,它基于人工神经网络的学习算法。深度学习在图像和语音识别、自然语言处理、医学图像分析、药物发现、自动驾驶汽车等领域取得了显著的进展。以下是围绕深度学习的几个关键主题的阐述。 学习路线 基础数学: 了解线性代数…...
mysql5.7数据库安装及性能测试
mysql5.7数据库安装及性能测试 记录Centos7.9下安装mysql 5.7并利用benchmark工具简单测试mysql的性能。 测试机:centos7.9 配置:4C8G40G 1. 下安装mysql5.7 安装mysql5.7: # 通过官方镜像源安装$ wget http://dev.mysql.com/get/mysql57-com…...

聪明与诚实:社会信任的桥梁
在现代社会中,我们经常听到这样的评价:“某人真聪明。”然而,当我们深入思考时,会发现“聪明”这个词背后所承载的含义并不单一。聪明和狡诈往往被混淆,而诚实的价值却时常被忽视。在一个高度诚信的社会里,…...

基于单片机的无线数据传输系统设计
摘要:基于单片机的无线数据传输系统的设计,实现了温度和湿度的自动采集、无线通讯和报警功能。该系统包括了LCD1602显示电路、DHT11温湿度采集电路等,完成了基于无线数据传输的方法来实现温湿度的采集。 关键词:温湿度检测;N RF 24 L 01;单片机 0 引言 随着科技水平的提高,…...

【IP:Internet Protocol,子网(Subnets),IPv6:动机,层次编址:路由聚集(rout aggregation)】
文章目录 IP:Internet Protocol互联网的的网络层IP分片和重组(Fragmentation & Reassembly)IP编址:引论子网(Subnets)特殊IP地址IP 编址: CIDR子网掩码(Subnet mask)转发表和转发…...
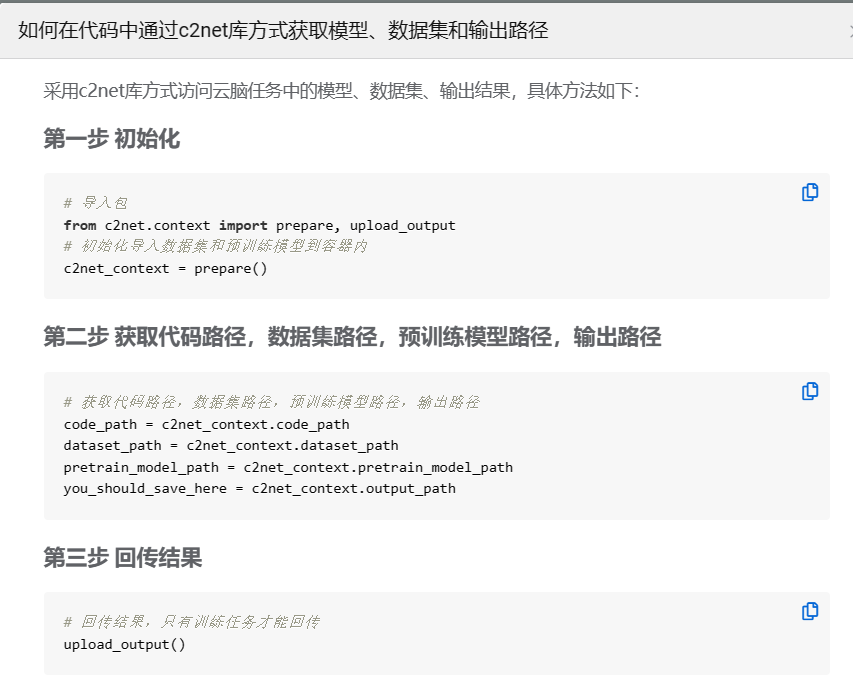
智启算力平台基本操作
智启算力平台 智启算力平台路径搭载数据集搭载镜像配置 智启算力平台 开发文档 帮助文档 - OpenI - 启智AI开源社区 路径搭载 OpenIOSSG/promote: 启智AI协作平台首页推荐组织及推荐项目申请。 - notice/Other_notes/SDKGetPath.md at master - promote - OpenI - 启智AI开…...
whisper模型微调
Whisper模型详解及其微调过程 一、引言 在人工智能领域中,自动语音识别(ASR)技术一直是一个热门且挑战性的研究方向。近年来,随着深度学习技术的快速发展,ASR技术取得了显著的进步。其中,OpenAI的Whisper…...
如何设计学术会议海报?
在参加学术会议的时候,制作一份会议海报来展示你的研究内容是十分必要的。海报是你与别人交流研究成果时的关键部分,也是成功科研生涯的重要元素。海报本身自带许多优秀的特质:思路清晰、内容精练,并且极易引起他人的兴趣。 一、…...

maven项目的设置
...
【哈希】Leetcode 205. 同构字符串【简单】
同构字符串 给定两个字符串 s 和 t ,判断它们是否是同构的。 如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。 每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上&am…...
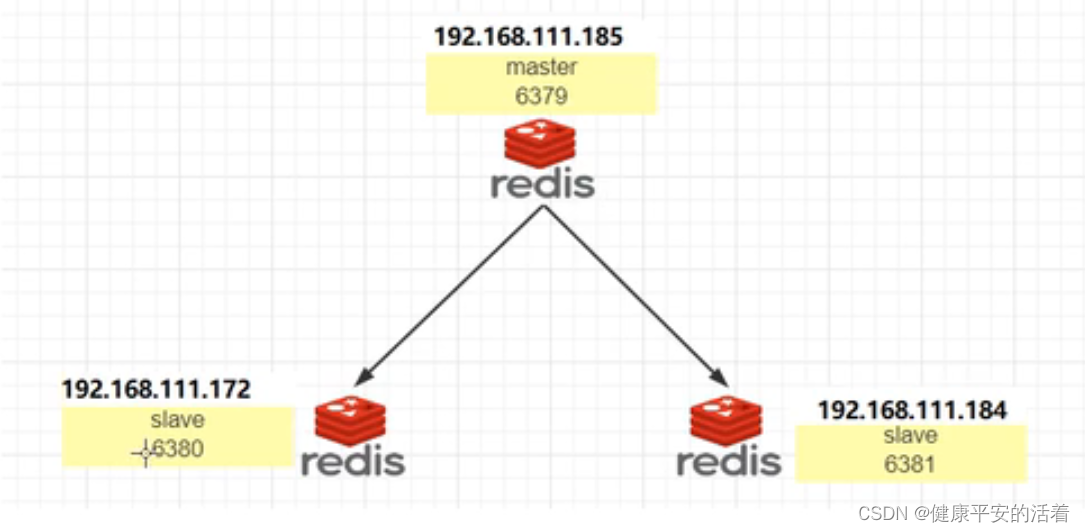
redis7基础篇2 redis的3种模式(主从,哨兵,集群)模式
一 主从复制模式 1.1 主从模式 主从模式: 主机可以读,写,重机只能写操作。 主机shutdown后,从机上位还是原地待命:从机不动,原地待命,数据正常使用,等待主机重启归来。 主机shu…...

一线互联网大数据面试题核心知识库(100万字)
本面试宝典涵盖大数据面试高频的所有技术栈,包括Liunx&Shell基础,Hadoop,Zookpeer,Flume,Kafka,Hive,Datax,Maxwell,DolphinScheduler,Spark Core&SQ…...